A Building Block is a combination of server and storage which provides a modular
approach for data management.
This building block guide illustrates how to choose the right number of deduplication
nodes depending on your environment, storage requirements and the production data
size. Choosing right deduplication model will allow you to protect large amount
of data with minimal infrastructure, faster backups and better scalability.
Server
For building block, you must choose efficient servers with fastest processors
and effective memory that delivers good performance and scalability.
Storage
Before setting up building block, make sure that you plan for sufficient storage
space that balances the cost, availability and performance. Sufficient storage space
includes:
The Building Block requires following suggested hardware specifications:
Configuration
Details
Server Specification (Operating System)
X64 Operating System
Minimum Dual Core CPU, Quad Core
32 GB RAM
Windows / Linux
Data Throughput Port
1 exclusive 10 GigE ports
(OR)
4, 1 GigE ports
May need NIC Teaming on Host
Disk Library Configuration
Network Attached Storage (NAS)
Exclusive 10 GigE port
7.2 K RPM SAS spindles
(OR)
SAS / FC / iSCSI
SAS: 6 Gbps HBA
FS: 8 Gbps HBA
iSCSI: Exclusive 10 Gbps NIC
7.2 K RPM SATA/SAS spindles
Min. RAID 5 Raid groups with 7+ spindles each
2 - 8 TB LUNs up to 50 LUNs
Dedicated Storage Adaptors
Deduplication Database (DDB) LUN
The deduplication
database needs to be on a fast disk for optimal backup performance. Before
setting up the deduplication database, the storage volumes must be validated
for high performance. This can be done using IO meter tool which measures
the IOPs (Input Output Operations per second). The following table illustrates
the recommendation on DDB volume size and IOPs ratings.
Deduplication is centrally managed through storage policies. Each storage policy
can maintain its own deduplication settings or can be associated to a global deduplication
storage policy. Depending upon the type of data and production size you can use
dedicated storage policy or global deduplication policy.
A dedicated deduplication storage policy consists of one library, one deduplication
database and one or more MediaAgents. For scalability purposes, using a dedicated
deduplication policy allows for the efficient movement of very large amounts
of data.
Dedicated policies are recommended, when backing up large amount of data
with separate data types that do not deduplicate well against each other such
as database and file system data.
Global deduplication storage policy provides one large global deduplication
store which can be shared by multiple deduplication storage policy copies. Each
storage policy can manage specific content and its own retention rules. However,
all participating storage policy copies share the same data paths (which consists
of MediaAgents and Disk Library mount paths) and the global deduplication store.
Client computers - subclients cannot be associated to a Global
Deduplication Storage Policy. They should be associated only to
standard storage policies.
Once a storage policy copy is associated to a Global Deduplication
Storage Policy, you cannot change the association.
Multiple copies within a storage policy cannot use the same
Global Deduplication Storage Policy.
Global deduplication policy are recommended:
Data that exists in multiple remote sites and is being consolidated
into a centralized data center.
For small data size with different retention requirements.
Deduplication database maintains all signature hash records for a deduplication
storage policy. This database can scale to maximum of 750 million records. This
limit is equivalent to 90 TB of data residing on the disk library and 900 TB of
production data (application data), assuming a 10:1 deduplication ratio. For better
performance, it is suggested to have 50 concurrent connections or streams for deduplication
database.
It is always recommended to host a single deduplication database per node. However,
certain workloads may require higher concurrency but lower capacity (e.g., DLO solutions).
In this case, maximum of 2 deduplication databases are recommended on a given deduplication
database MediaAgent. Note that these deduplication databases must be hosted on different
disk drives.
Also, it is recommended that to locate the deduplication database locally on
the MediaAgent. The faster the disk performance the more efficient the data protection
and deduplication process will be.
The Disk Library consists of disk devices that point to the location of the Disk
Library folders. Each disk device may have a read/write path or read only path.
The read/write path is for the MediaAgent controlling the mount path to perform
backup. The read only path is for the alternate MediaAgent to be able to read the
data from the host MediaAgent. This is to allow for restores or auxiliary copy operations
while the local MediaAgent is busy.
During the deduplication backups:
It is recommended to use dedicated disk libraries for each MediaAgent.
Non-deduplication data should backup to a separate disk library.
Configuring the data types into separate disk libraries allows for easier
reporting on the overall deduplication savings.
If the non-deduplicated and deduplication data are written to the single library,
it will skew the overall disk usage information and make space usage prediction
difficult.
Each Building Block can support 100 TB of disk storage. The disk storage should
be partitioned into 2 � 4 TB LUNs and configured as mount points in the operating
system. This LUN size is recommended to allow for ease of maintenance for the Disk
Library. Additionally, a larger array of smaller LUNs reduces the impact of a failure
of a given LUN.
For disk storage the mount paths can be divided into two types:
NAS paths (Disk Library over shared storage)
This is the preferred method for a mount path configuration.
In NAS paths the disk storage is on the network and the MediaAgent connects
through a network protocol.
If a MediaAgent goes offline, the disk library is still accessible by
other MediaAgents in the library.
Direct Attached Block Storage (Disk Library over Direct Attached Storage)
In direct attached block storage (SAN) the mount paths are locally attached
to the MediaAgent.
If a MediaAgent is lost then the disk library is offline. Secondly,
all network communication to the mount path occurs from the MediaAgent to
the NAS device.
In a direct attached design, configure the mount paths as mount points
instead of drive letters. This allows for larger capacity solutions to configure
more mount paths than the drive letters.
Smaller capacity sites can use drive letters as long as they do not
exceed the number of available drive letters.
By default, the deduplication storage policy block size is set to 128 K. This
recommendation is for all data types other than databases larger than 1 TB.
For large databases, the block size can be configured to 256 K (1 TB to 5 TB)
or 512 K (> 5 TB) and should be configured without software compression enabled
at the policy level. Any block from 4 K to the configured block size will automatically
be hashed and checked into the deduplication database.
Block size can be configured from the Storage Policy Properties - Advanced tab.
When configuring the global deduplication policy, all other storage policy copies
that are associated with the global deduplication policy must use the same block
size. To modify the block size of global deduplication policy, see
Block Size for Global Deduplication for step-by-step instructions.
By default, when a deduplication storage policy is configured, compression is
automatically enabled on policy level. This settings will override the subclients
compression settings. For most data types compression is recommended. This compresses
the blocks and generates a signature hash on the compressed block.
For database agents, data compression is not recommended as it performs compression
on the data before handing it off to the database agent which causes the data to
expand.
When global deduplication storage policy is configured, this settings will override
the storage policy and the subclients compression settings.
The stream configuration in a Storage Policy design is also important. When a
Round-Robin design is configured, ensure the total number of streams across the
storage policies associated to the Global Deduplication Storage Policy does not
exceed 50. This ensures that no more than 50 jobs will protect data at a given time
and overload the deduplication database.
For example, a Global Deduplication Storage Policy may have four associated storage
policies with 50 streams each for a total of 200 streams. If all storage policies
were in concurrent use, the deduplication database would have 200 connections and
performance would degrade. By limiting the number of writers to a total of 50, all
200 jobs may start, however, only 50 will run at any one time. As resources become
available from jobs completing, the waiting jobs will resume.
Consider the following when using SAN storage for Data Path configuration:
When using SAN storage for the mount path, use Alternate Data Paths -> When
Resources are offline -> immediately.
If a data path fails or is marked offline for maintenance, the job will
failover to the next data path configured in the Data Path tab.
Although Round-Robin between Data paths will work for SAN storage
it�s not recommended because of the performance penalty during DASH copies and
restores. This is because of the multiple hops that have to occur in order to
restore or copy the data.
Consider the following when using NAS storage for Data Path configuration:
When using NAS storage for the mount path, Round Robin, between Data Paths
is recommended. This is configured in the Storage Policy copy properties
-> Data Path Configuration tab of the storage policy associated to the
global deduplication policy and not in the Global Deduplication Policy
properties.
NAS mount paths do not have the same performance penalty because the network
communication is between the servicing MediaAgent and the NAS mount path directly.
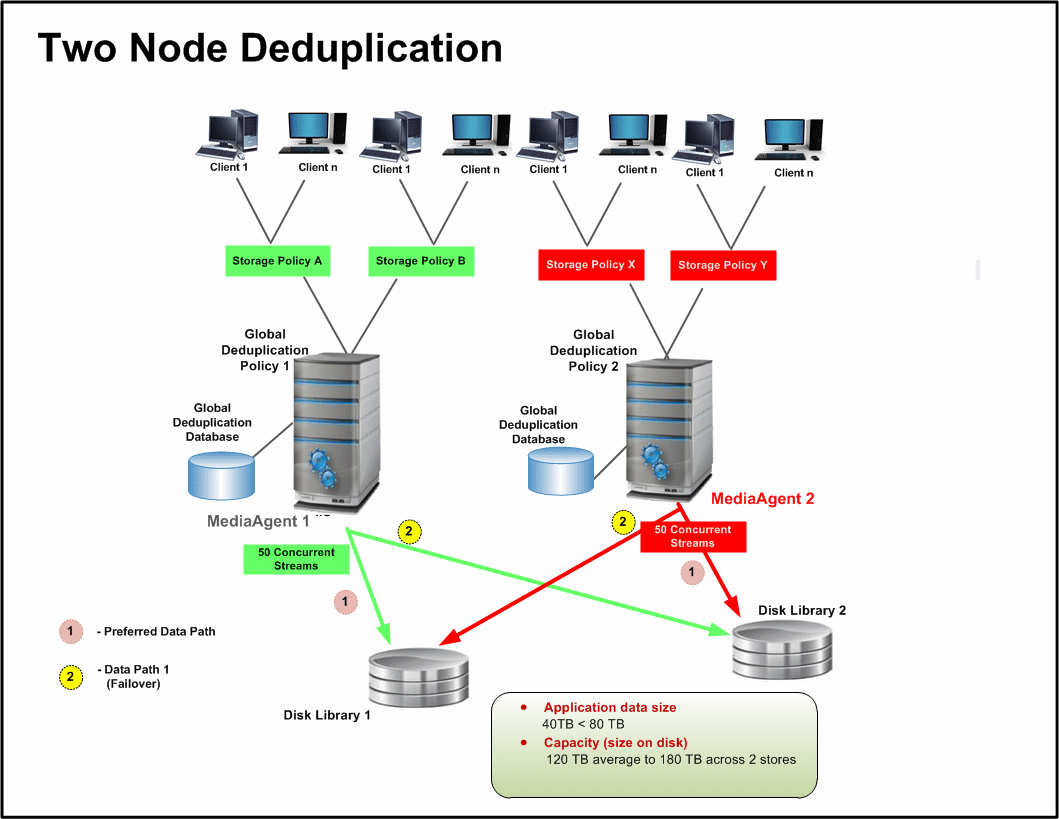
Single node deduplication is useful in small and ad-hoc environments where the
production (application) data is approximately 40 TB or less. This can be configured
in one of the following way:
For small environments, that do not contain a large amount of data but different
retention settings are required, then multiple storage policy copies can be associated
with a global deduplication policy.
This method is recommended for small environments with the data path defined
through a single MediaAgent.
By default the compression settings is enabled on the global deduplication
policy. Depending upon the application data type make sure to turn on/off
the compression settings.
Additionally, you can create a storage policy for data storage or
for one or more storage policies with different retention requirement
and associate them to the global deduplication policy.
By default the compression settings is enabled on the global deduplication
policy. Depending upon the application data type make sure to turn on/off
the compression settings.
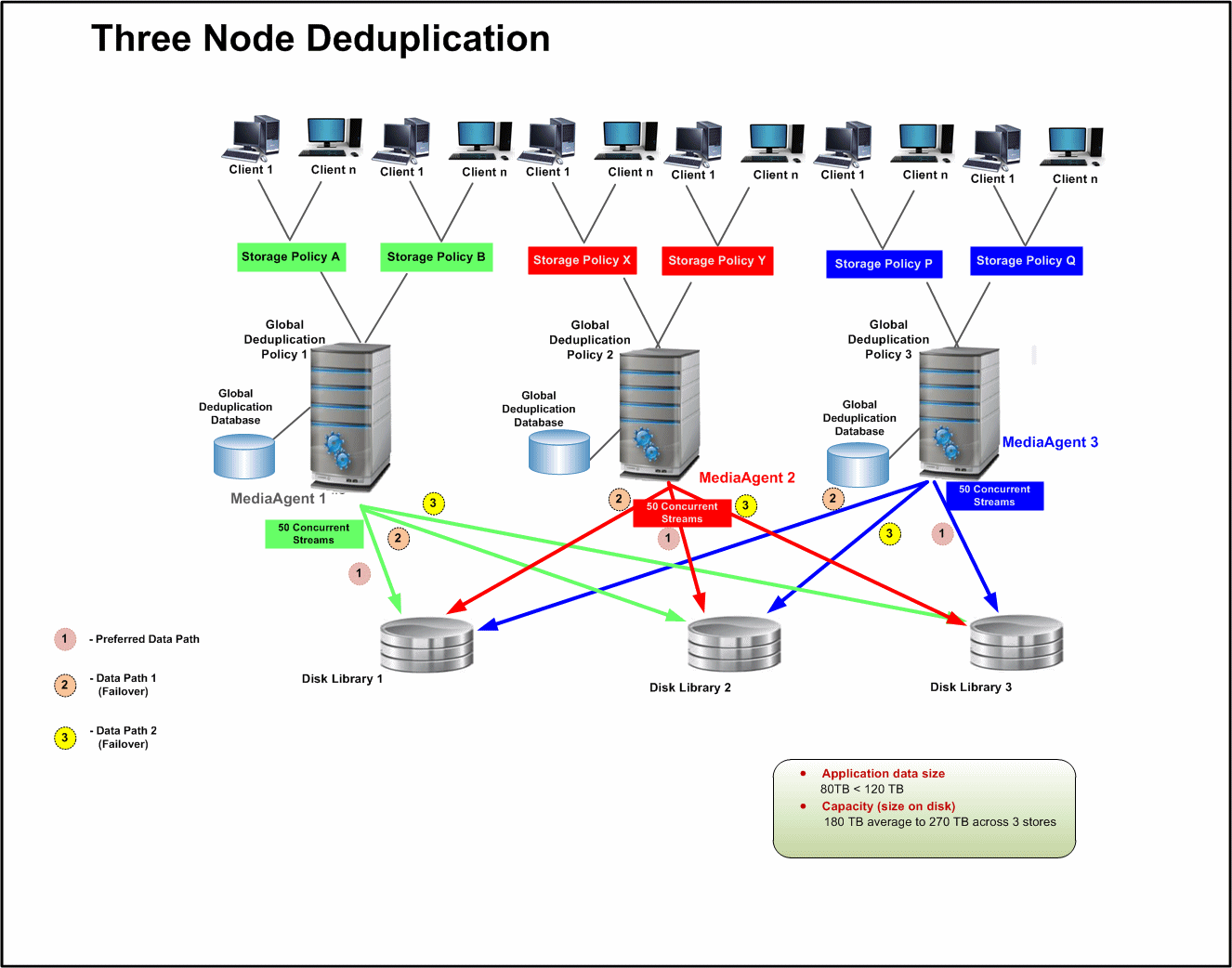
Three node deduplication is useful to protect the production data more than 80
TB and less than 120 TB. This model uses:
Three global deduplication policy (one per node)
Three disk library shared across three nodes
Three deduplication database (one per node)
Three MediaAgents
This setup holds:
Capacity (size on disk) - 180 TB average to 270 TB across 3 stores
Throughput - 6 TB/hr Average (12 TB/hr max)
Concurrency - 150 Streams across three stores
Disk Library Shared between both nodes - Up to 50 X 2 - 8 TB LUNs per node
(requires read-only shares to other node) or Shared NAS storage between both
nodes
Use the following steps to setup three deduplication nodes:
By default the compression settings is enabled on the global deduplication
policy. Depending upon the application data type make sure to turn on/off
the compression settings.
In a larger environment, certain data types do not deduplicate
well against others such as database data against file system data. In addition,
data types from application such as SQL and Oracle will perform application
level compression, where as file system data may not.
So, for the best
performance and scalability when backing up different data types (File System
data, SQL data and Exchange data), it is best practice to have different
global deduplication policies to protect different data types.
During this setup, set recommended block size depending upon the data
type.
By default, the block size is set to 128 K, for large databases
it is recommended to set to 256 K to allow for higher scalability.
The diagram on the right describes different data types using separate
global deduplication policy to protect and manage deduplicated data.
Using the File System Agent is a preferred method for a deduplication database
backup. This method allows the periodic backup of the deduplication database without
requiring jobs to pause. This is done as follows:
Installing File System iDataAgent as a Restore Only Agent (which does not
consume license) on the MediaAgent hosting the deduplication database.
Configuring the file system subclient by selecting DDB Subclient
option, this will automatically define the deduplication database as the subclient
content.
Scheduling the deduplication database backup job as frequently as desired
for database protection.
When the deduplication database backup job is initiated:
All communication to the active deduplication database is paused for
a few seconds. The information in memory is committed to disk to ensure
the deduplication database is in a quiesced state.
It quickly creates a snapshot of the volume using VSS (Windows) / LVM
(Unix) snapshots.
Unix platform also support Extended 3 File System (ext3),
and VERITAS Volume Manager (VxVM) file systems.
If you have configured LVM volumes, ensure
that enough disk space is available to accommodate LVM snapshots.
It is recommended that you have atleast 15% of unallocated space
on the volume group.
Also, make sure that the amount of COW space
to reserve while creating snapshots is atleast set to 10% of the
Logical Volume size. See
How
to resize COW space size for snapshot creation? for step-by-step
instructions.
Once the snapshot is created, all the communication to the deduplication
database is resumed and it automatically backs up the deduplication database
from that snapshot.
After a deduplication database has been backed up successfully, the snapshot
is deleted. Throughout this time, the Job Controller will show the jobs in a
running state.
This method backs up all active (non-sealed) deduplication databases available
in that MediaAgent.
In the event of deduplication store failure, the reconstruction job is automatically
initiated which will restore from the deduplication backup. During this process:
Add the new records into the restored deduplication database for all the
backups that went to the deduplication database after the backup, till the point
of offline.
Prune those records of the backups which got aged and pruned after the last
deduplication backup till the point of offline.
After the completion of the data aging job scheduled on the CommServe, the physical
pruning on the disk library begins. The best time to run the deduplication database
backup is when all the physical pruning of the data blocks on the disk library is
complete, so that the reconstruction job that uses the deduplication database snapshot
from this backup job will not have to replay that many prune records. The physical
pruning usually takes a few hours after the completion of the data aging job. So
statistically, it will be good to run the deduplication database backup at the mid
point between two Data Aging jobs.
So for example, if the data aging is scheduled to run for every 6 hours, the
recommended schedules are:
Data Aging: Every 6 hours starting at 3:00 AM.
Deduplication Database Backup: Every 6 hours starting at 6:00 AM.
Schedule the deduplication database backup in such a way that it runs when there
are a fewer backups in progress as possible. This will ensure that the deduplication
database backup will finish sooner.
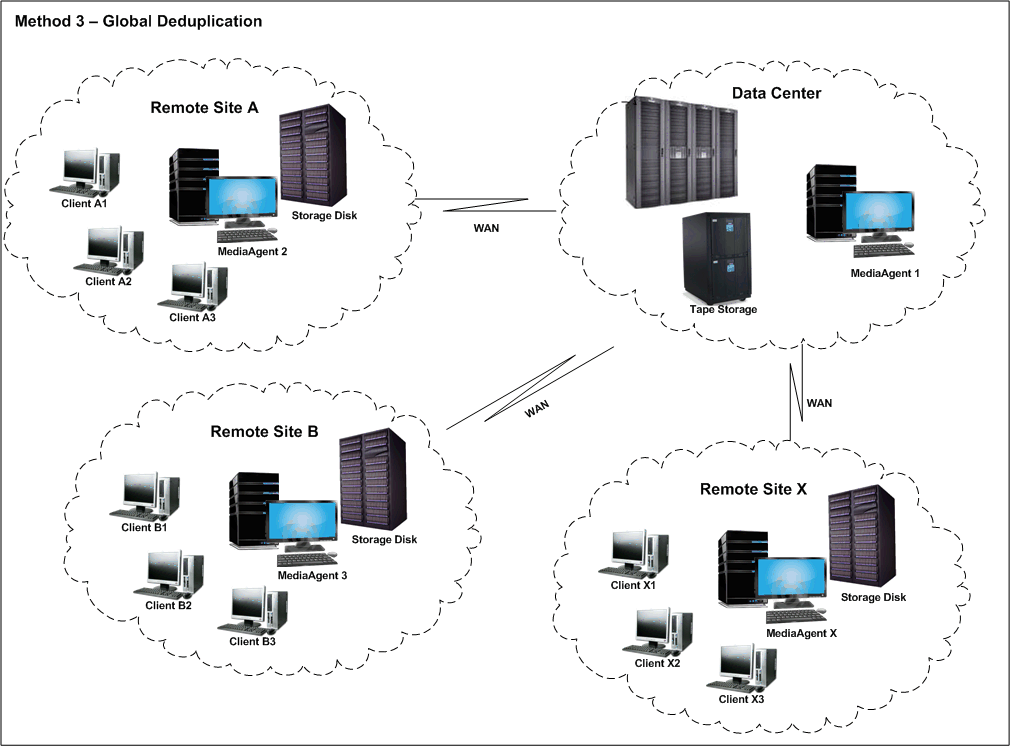
Consider a setup with multiple remote sites and a centralized
data center. Each remote site backs up the internal data using individual
storage policies and saves a copy of the backup on the centralized data
center. Here, though the redundant data within the individual backup can
be eliminated using deduplication on primary copies at the remote site,
the secondary copies stored at the data center might still contain redundant
data among the copies. This redundant data can be identified and eliminated
using global deduplication.