Full backups provide the most comprehensive protection of data.
Backups for any client start with a full backup. The full backup becomes a
baseline to which subsequent backup types are applied. For example, a full
backup must be performed before a transaction log backup can be initiated.
Use the following steps to run a full backup:
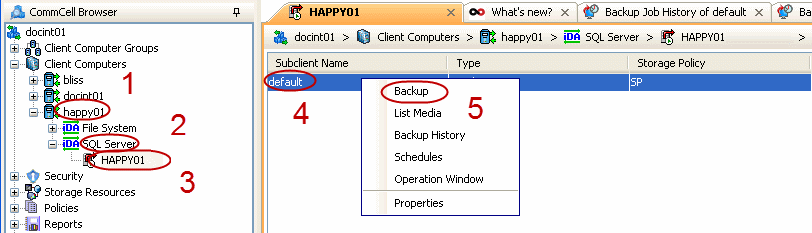
From the CommCell Browser, navigate to Client Computers |
<Client> | SQL Server.
Right-click an <Instance> and click Backup All
Subclients.
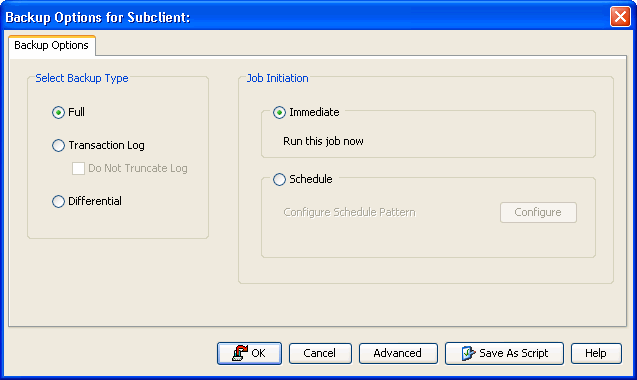
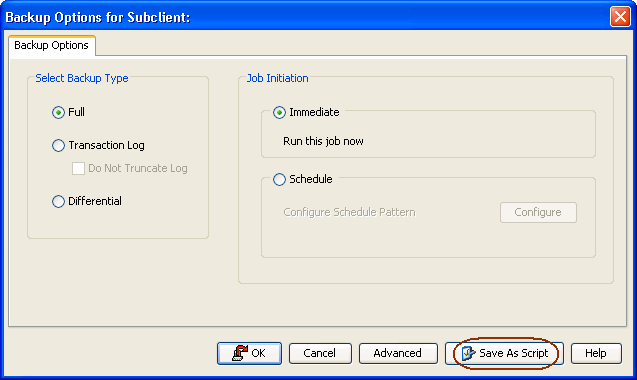
Select Full
as the backup type and click Immediate.
Click OK.
You can track the progress of the job from the Job Controller.
When the backup has completed, the Job Controller displays Completed.
A transaction log backup captures the transaction log which contains a record of all
committed or uncommitted transactions. Transaction log
backups are consistent with the start time of the backup.
The use of transaction log backups make point-in-time recovery possible. This
is useful in the scenario of a database failure where it is unacceptable to lose
any data and you want to restore to the point of failure. If you use only full
and differential backups, you will be able to restore to the time of the backup,
but not to a point-in-time between backups.
A transaction log backup is similar to a traditional incremental backup you
might perform on a file system because the transaction log backup contains only
the new changes since the full or another transaction log backup.
Each time a transaction log is backed up it is truncated to the exact time of
the backup. No checkpoint is issued at this time, therefore dirty pages are not
written to disk before or after a transaction log backup. If there are dirty
pages, any completed transactions will need to be rolled forward if a
transaction log restore is performed. Any transactions that are not completed at
the time a transaction log backup is performed are rolled back during a restore
involving a transaction log backup.
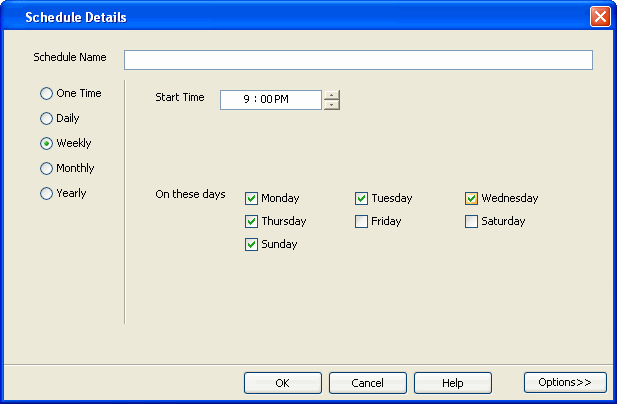
Use the following steps to run a transaction log backup:
Ensure that the SQL Server database is in full or bulk-logged recovery
mode.
From the CommCell Browser, navigate to Client Computers |
<Client> | SQL Server |
<Instance>.
Right click a <Subclient> and click Backup.
Select Transaction Log
as backup type.
Click Immediate.
Click
OK.
You can track the progress of the job from the Job Controller.
When the backup has completed, the Job Controller displays Completed.
You can start
a Transaction Log backup automatically after a successful Full or Differential
backup. This is useful when you want to back up logs
immediately after a data backup, and allows you to do so without creating two
scheduled jobs.
Use the following steps to automatically run a transaction log after a backup:
From the CommCell Browser, navigate to Client Computers | <Client>
| SQL Server | <Instance>.
Right click an <Subclient> and click Backup.
Select Full or Differential backup type and click Immediate.
Click Advanced.
Click Start Log
Backup After Successful Backup.
Click
OK.
You can track the progress of the job from the Job Controller.
When the backup has completed, the Job Controller displays Completed.
Note that the simultaneous running of file or file group backup jobs is not
supported.
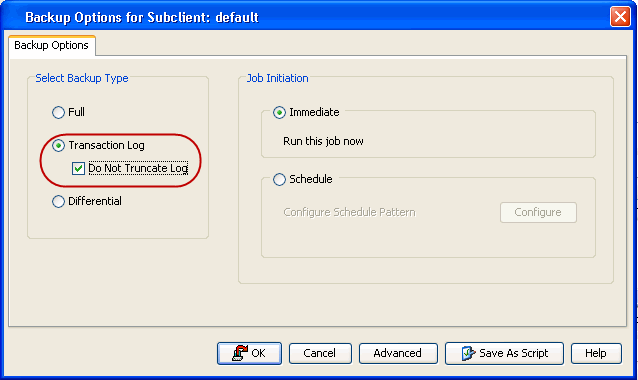
If you experience a database failure and you want to restore to the point of
failure, a Transaction Log Backup with Do not truncate log must be
initiated. This backups the database when it is damaged, regardless of its
state.
It is used for capturing all transaction log events occurred since the last
backup was run. This operation does not empty the active transaction log.
Use the following steps to disable log truncation during a backup:
Ensure that the SQL Server database is in full or bulk-logged recovery
mode.
From the CommCell Browser, navigate to Client Computers |
<Client> | SQL Server |
<Instance>.
Right click a <Subclient> and click Backup.
Select Transaction Log
as backup type.
Select Do Not Truncate Log.
Click Immediate.
Click
OK.
You can track the progress of the job from the Job Controller.
When the backup has completed, the Job Controller displays Completed.
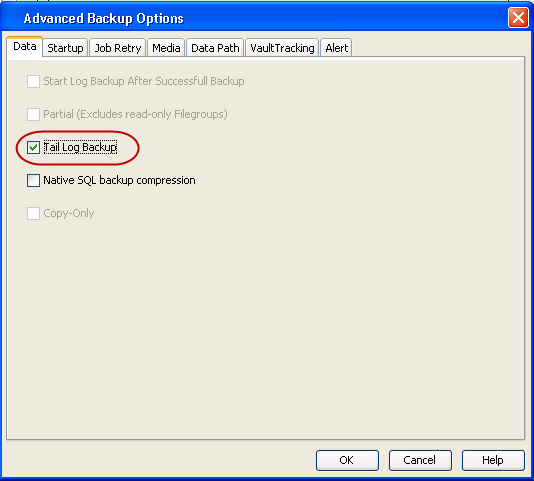
When backing up transaction logs, you can choose to back up the tail of the
log to capture the log records that have not yet been backed up. A tail-log
backup prevents work loss and keeps the log chain intact. A tail-log backup
allows you to recover a database to the point of failure; otherwise you can only
recover a database to the end of the last backup that was created before the
failure. For example, if a database was damaged or a data file was deleted, you
should run a tail-log backup before attempting a file/file group restore. After the log tail is backed
up, the database will be left in the RESTORING state.
Use the following step to backup the tail of a transaction log:
Ensure that the SQL Server database is in full or bulk-logged recovery
model. To view or change the recovery model of a database:
After connecting to the appropriate instance of the Microsoft SQL
Server Database Engine, in Object Explorer, click the server name to
expand the server tree.
Expand Databases, and, depending on the database, either
select a user database or expand System Databases and select a
system database.
Right-click the database, and then click Properties, which
opens the Database Properties dialog box.
In the Select a Page pane, click Options.
The current recovery model is displayed in the Recovery model
list box.
Select either Full or Bulk-logged.
From the CommCell Browser, navigate to Client Computers |
<Client> | SQL Server |
<Instance>.
Right click a <Subclient> and click Backup.
Select Transaction Log
as backup type.
Click Immediate.
Click Advanced.
Click Tail Log Backup.
Click
OK.
You can track the progress of the job from the Job Controller.
When the backup has completed, the Job Controller displays Completed.
Note that the simultaneous running of file or file group backup jobs is not
supported.
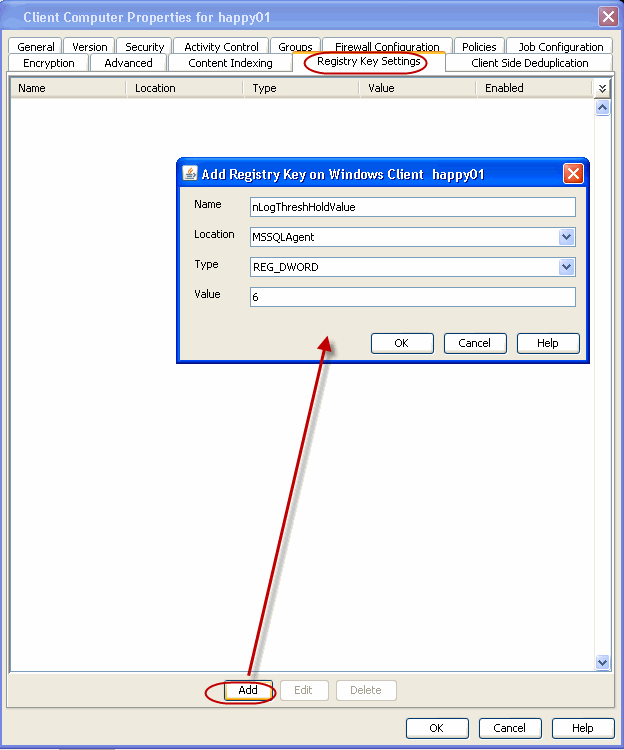
Full backups are necessary at regular intervals as it reduces the chance of data
loss if one of log backup becomes corrupted as it will invalidate (not
restorable) all other log backups performed after that. This key is used for the
purpose of re-enforcing the need of a full backup after certain number of
transaction log backups have run.
When this registry key is configured,
a minor event will be generated in the Event Viewer to remind users to run a full backup after the
configured number of transaction log backups have run.
Use the following steps to configure the number of log backups:
From the CommCell Browser, navigate to Client Computers.
Right-click the <Client> in which you want to add
the registry key, and then click Properties.
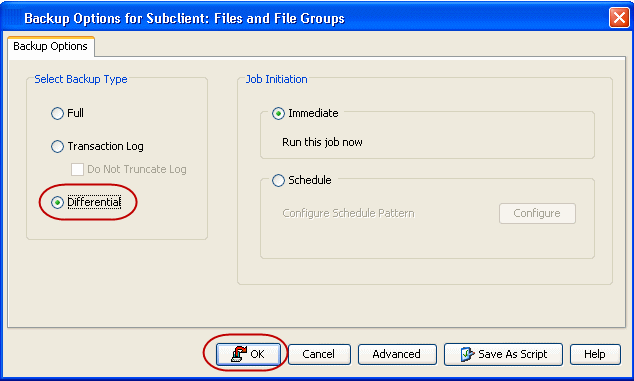
A differential backup contains only the data that is new or has been changed since
the last full backup. Differential backups consume less media and use less resources than full backups.
Differential backups are cumulative. This means that each differential backup
contains all changes accumulated since the last full backup. Each successive
differential backup contains all the changes from the previous differential
backup.
Use the following steps to run a differential backup:
From the CommCell Browser, navigate to Client Computers |
<Client> | SQL Server |
<Instance>.
Right-click a <Subclient> and click Backup.
Select Differential
as the backup type and click Immediate.
Backups can be compressed before it is backed up to reduce the size of the backup.
Typically, compressing a backup will require less device I/O which should
increase backup speed significantly. However, CPU usage may increase for
compressed backups and you may need to evaluate performance counters. Scheduling
the backup during off-peak hours or compressing only low-priority backups may be
desirable.
When using compression, there is no need for deduplication as the
data will already be compressed and deduplication will not consequently save any
more space.
Use the following steps to enable compression:
From the CommCell Browser, navigate to Client Computers |
<Client> | SQL Server |
<Instance>.
Right-click a <Subclient> and click Backup.
Select a backup type and click Immediate.
Click Advanced.
Click Native SQL backup compression.
Click
OK.
You can track the progress of the job from the Job Controller.
When the backup has completed, the Job Controller displays Completed. Note that the simultaneous running of file or file group backup jobs is not
supported.
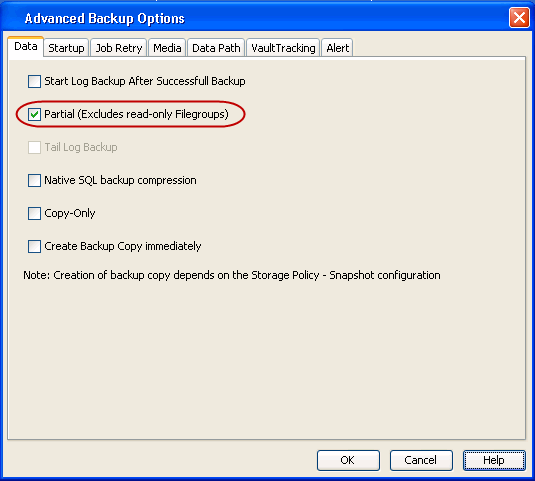
Partial backups are useful whenever you want to exclude read-only file groups. A
partial backup is not supported when backing up transaction logs.
Use the following steps to enable partial backups:
From the CommCell Browser, navigate to Client Computers |
<Client> | SQL Server |
<Instance>.
Right-click a <Subclient> and click Backup.
Select a backup type and click Immediate.
Click Advanced.
Click Partial (Excludes read-only Filegroups).
Click
OK.
You can track the progress of the job from the Job Controller.
When the backup has completed, the Job Controller displays Completed.
Note that the simultaneous running of file or file group backup jobs is not
supported.
You can perform backups of one or more SQL databases from the command line
interface.
Command line backups enable you to perform backup operation on multiple clients
simultaneously. In order to run the backups from command line, you need an input xml file
which contains the parameters for configuring the backup options. This input xml
file can be obtained from one of the following ways:
Download the
input xml file template and save it on the computer from where the
backup will be performed.
Generate the input xml file from the CommCell Console and save it on the
computer from where the backup will be performed.
In addition to the parameters provided in the template xml file, if you want
to include additional options for the backup, you can do so by selecting the
required options from the CommCell Console and generate the command line xml
script for the backup.
Follow the steps given below to generate a script which you can use to
perform a backup from the command line interface:
From the CommCell Browser, navigate to Client Computers |
<Client> | SQL Server |
<Instance>.
Right click an <Subclient> and click Backup.
Select the required backup options which you want to execute using the
script.
Click Save as Script.
Enter the location where you want to save the script or click
Browse and navigate to the location.
The script will be saved as a .xml file
and a .bat file is created.
If a file with the same name already exists in the specified location,
the .xml file will be created with a timestamp. However, the .bat file will
overwrite the existing file.
Enter the username and password for the user account which you want to
use to perform the backup.
By default, the user account which you have used to login to CommCell
console is used for performing the backup. However, if the user account does
not have access to any application or database, click Use a
different account.
Jobs that fail to complete successfully are automatically restarted based on
the job restartability configuration set in the Control Panel. Keep in mind that changes
made to this configuration will affect all
jobs in the entire CommCell.
To Configure the job restartability for a specific job, you can modify the
retry settings for the job. This will override the setting in the Control Panel. It is also possible to override the default CommServe configuration for individual
jobs by configuring retry settings when initiating the job. This configuration,
however, will apply only to the specific job.
Backup jobs for this Agent are resumed from the point-of-failure.
Configure Job Restartability at the CommServe Level
From the CommCell Browser, click Control Panel icon.
Select
Job Management.
Click Job Restarts tab and select a Job Type.
Select Restartable to make the job restartable.
Change the value for Max Restarts to change the maximum number of
times the Job Manager will try to restart a job.
Change the value for Restart Interval (Mins) to change the time
interval between attempts for the Job Manager to restart the job.
Click OK.
Configure Job Restartability for an Individual Job
From the CommCell Console, navigate to <Client> |
SQL Server | <Instance>.
Right-click the Subclient and select Backup
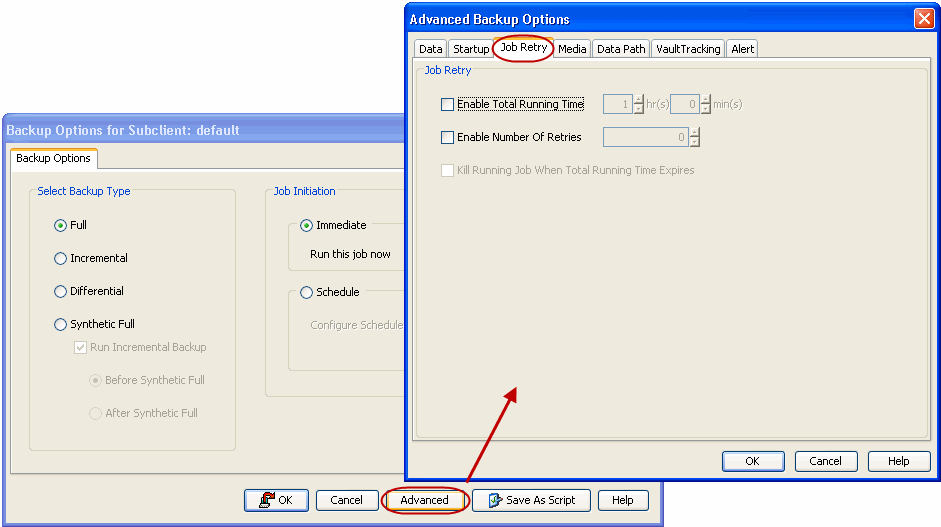
Click Advanced.
In the Advanced Backup Options dialog box, click the Job Retry tab.
Select Enable Total Running Time and specify the maximum elapsed
time before a job can be restarted or killed.
Select Kill Running Jobs
When Total Running Time Expires to kill the job after reaching the
maximum elapsed time.
Select Enable Number Of Retries and specify the number of
retries.
The following controls are available for running jobs in the Job Controller window:
Suspend
Temporarily stops a job. A suspended job is not
terminated; it can be restarted at a later time.
Resume
Resumes a job and returns the
status to Waiting, Pending, Queued, or Running. The status depends on
the availability of resources, the state of the Operation Windows, or
the Activity Control setting.
Kill
Terminates a job.
Suspending a Job
From the Job Controller of the CommCell Console, right-click the job and
select Suspend.
The job status may change to Suspend Pending
for a few moments while the operation completes. The job status then changes
to Suspended.
Resuming a Job
From the Job Controller of the CommCell Console, right-click the job and
select Resume.
As the Job Manager attempts to restart the job,
the job status changes to Waiting, Pending, or Running.
Killing a Job
From the Job Controller of the CommCell Console, right-click the job and
select Kill.
Click Yes when the confirmation prompt
appears if you are sure you want to kill the job. The job status may
change to Kill Pending for a few moments while the operation
completes. Once completed, the job status will change to Killed and
it will be removed from the Job Controller window after five minutes.
See
Job
Management for a comprehensive information on managing jobs.
The following table describes the available additional options to further
refine your backup operations:
Option
Description
Related topics
Startup Options
The Startup Options are used by the Job Manager to set priority for resource
allocation. This is useful to give higher priority to certain jobs. You can set
the priority as follows:
From the CommCell Browser, navigate to Client Computers | <Client>
| SQL Server | <Instance>.
Right-click the Subclient in the right pane and click Backup.
Click Advanced and click Startup tab.
Select the Change
Priority checkbox.
Enter a priority number - 0 is the highest priority and 999 is the
lowest priority.
Select the Start up in suspended State check box to start the job
in a suspended state.
This option enables users or user groups to get automatic notification on the
status of the data protection job. Follow the steps given below to set up the
criteria to raise notifications/alerts:
From the CommCell Browser, navigate to Client Computers | <Client> |
SQL Server | <Instance>.
Right-click the Subclient in the right pane and click Backup.
Click Advanced and select the Alert tab.
Click Add Alert.
From the Add Alert Wizard dialog box, select the required threshold and
notification criteria and click Next.
Select the required notification types and click Next.
Command Line Interface enables you to perform backups or restore from the command line. The
commands can be executed from the command line or can be integrated into scripts.
You can also generate command line scripts for specific operations from the CommCell
Browser using the Save As Script option.
The CommCell Readiness Report provides you with vital information, such as
connectivity and readiness of the Client, MediaAgent and CommServe. It is useful
to run this report before performing the data protection or recovery job. Follow the steps
given below to generate the report:
From the Tools menu in the CommCell Console, click Reports.
Navigate to Reports | CommServe | CommCell Readiness.
Click the Client tab and click the Modify button.
In the Select Computers dialog box, clear the Include All
Client Computers and All Client Groups check box.
The Backup Job Summary Report provides you with information about all the
backup jobs that are run in last 24 hrs for a specific subclient. You can get
information such as status, time, data size etc. for each backup job. It is useful
to run this report after performing the backup. Follow the steps
given below to generate the report:
From the Tools menu in the CommCell Console, click Reports.
Navigate to Reports | Jobs | Job Summary.
Click Data Management on the General tab in the right
pane.
Select the Computers tab.
Click Subclient and select the Edit tab.
Navigate to Client Computers | <Client> | File System | Backup Set |
Subclient.
Data Protection operations use a default Library, MediaAgent, Drive
Pool, and Drive as the Data Path. You can use this option to change the
data path if the default data path is not available. Follow the steps
given below to change the default data path:
From the CommCell Browser, navigate to Client Computers | <Client> |
SQL Server | <Instance>.
Right-click the Subclient in the right pane and click Backup.
Click Advanced and select the Data Path tab.
Select the MediaAgent
and Library.
Select the Drive Pool and Drive for optical and tape
libraries.
The Start New Media option enables you to start the data protection operation on
a new media. This feature provides control over where the data physically
resides. Use the following steps to start the data protection operation on a new
media:
From the CommCell Browser, navigate to Client Computers | <Client> |
SQL Server | <Instance>.
Right-click the Subclient in the right pane and click Backup.
This option marks the media as full, two minutes after the successful completion
of the data protection job. This option prevents another job from writing to
this media. Follow the steps given below:
From the CommCell Browser, navigate to Client Computers | <Client> |
SQL Server | <Instance>.
Right-click the Subclient in the right pane and click Backup.
The Allow Other Schedules to use Media Set option allows jobs that are part
of the schedule or schedule policy and using the specific storage policy to
start a new media. It also prevents other jobs from writing to the same set of
media.
From the CommCell Browser, navigate to Client Computers | <Client> |
SQL Server | <Instance>.
Right-click the Subclient in the right pane and click Backup.
Click Advanced and select the Media tab.
Select the Allow Other Schedules To Use Media Set check
box.
This option allows you to extend the expiration date of a specific job. This
will override the default retention set at the corresponding storage policy
copy. Follow the steps given below to extend the expiration date:
From the CommCell Browser, navigate to Client Computers | <Client> |
SQL Server | <Instance>.
Right-click the Subclient in the right pane and click Backup.
Click Advanced and select the Media tab.
Select one of the following options:
Infinite - Select this option to extend the expiration date by
infinite number of days
Number of day - Select this option to specify the number of days
to extend the expiration date and then enter the number of days.
This feature provides the facility to manage media that is removed from a
library and stored in offsite locations. Depending on your VaultTracker setup,
select the required options. Use the following steps to access and select the
VaultTracker options.
From the CommCell Browser, navigate to Client Computers | <Client> |
SQL Server | <Instance>.
Right-click the Subclient in the right pane and click Backup.