When the database is corrupted or lost, you can restore and recover it from
the latest offline or online full backup (depending on how the subclient was
configured for backups).
By default, the database is restored to the same location from where it was
backed up. Once the database is restored, it is recovered to the current time.
Use the following steps to restore and recover a database to the same host:
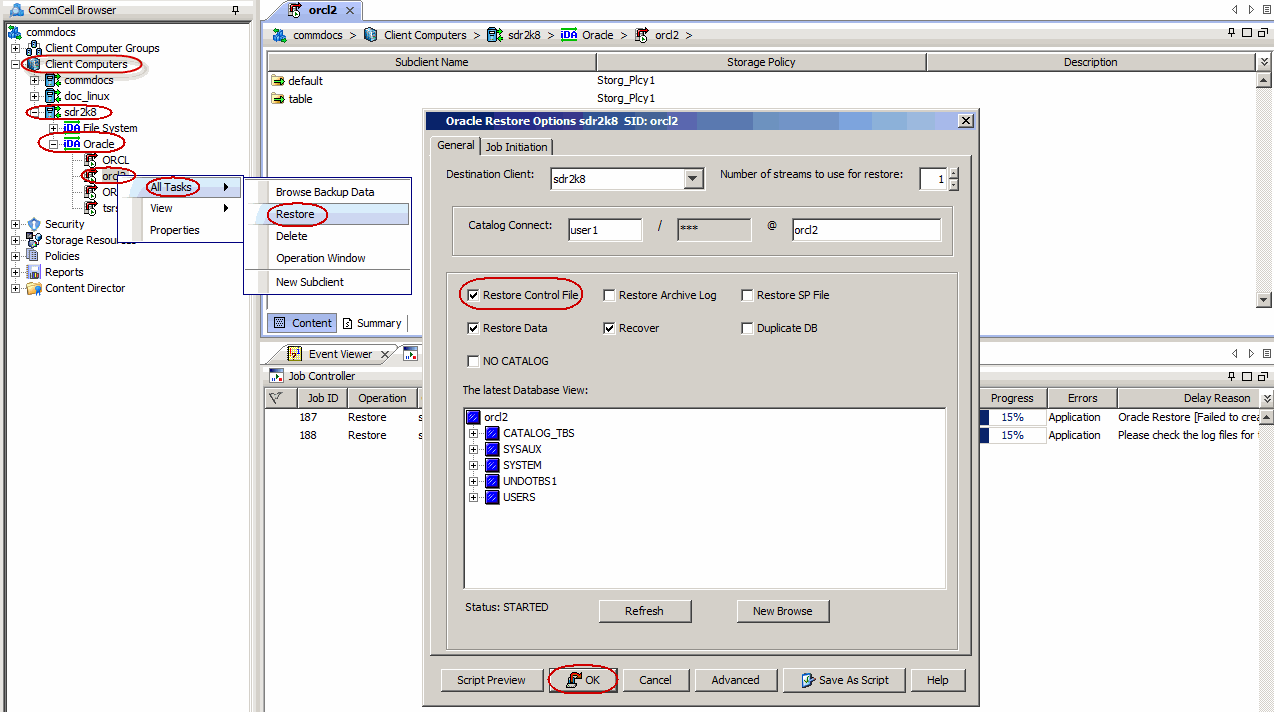
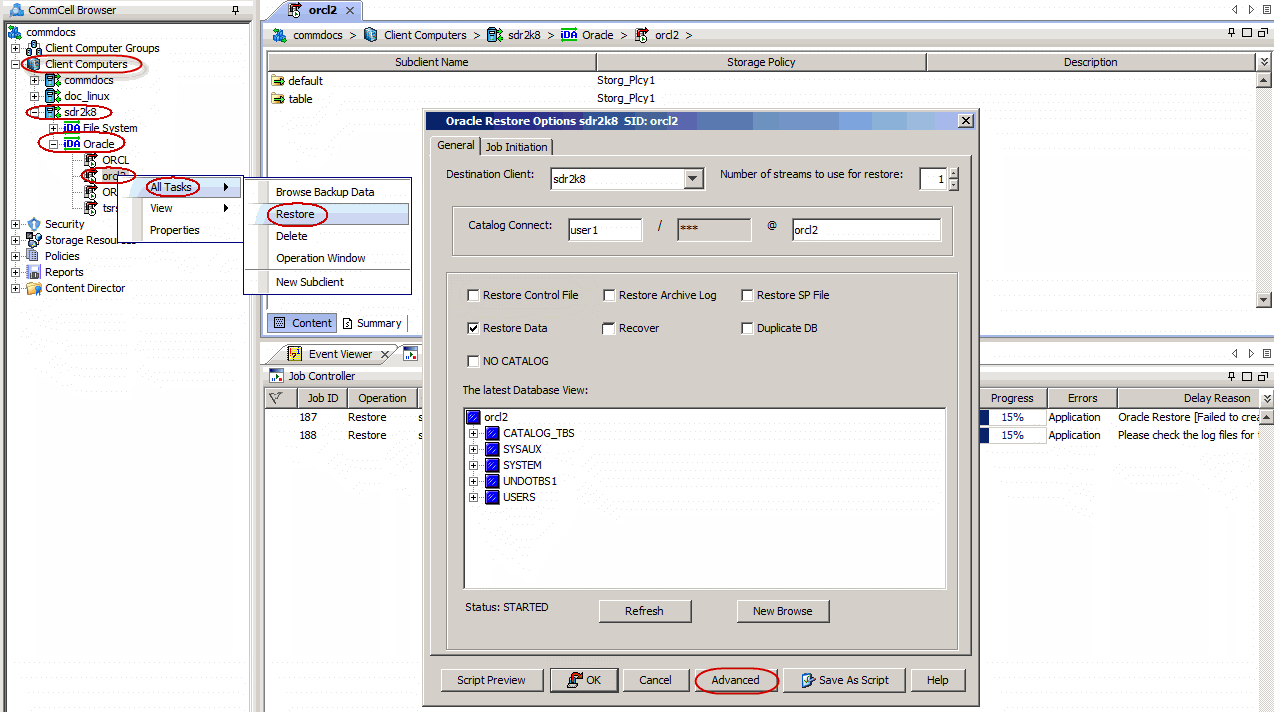
From the CommCell Browser, navigate to Client Computers |
<Client> | Oracle.
Right-click the <Instance>, point to All Tasks
and then click Restore.
Verify that the Restore Data and Recover options
are selected.
If the computer on which you hosted a database is damaged or destroyed, you can
restore and recover the lost database with the same directory structure on to a new
host.
By default, the database is restored in the ARCHIVELOG mode, You can also
choose to restore the db in NOARCHIVELOG mode.
Use the following steps to restore and recover a database to a new host with
the same directory structure:
Prerequisites
Verify the following in both the source and destination computers:
The connection specifications (host, service name, port) in the
tnsnames.ora file on both the source and
destination computers should be different.
The <username> you use for the destination computer is different
than the username for the source computer.
Sufficient disk space is available on the destination computer to
accommodate the restored database.
Both the source and destination computers should have the following
similar features:
Operating systems
Oracle version
ORACLE_SID
init <SID>.ora file
Processor (32-bit or 64-bit)
Datafile directory structures
Setting up the Source and Destination Hosts
Create a new user account
with recovery catalog owner permission within the Recovery Catalog for the destination computer.
Use a different <username>
Example:
SQL>create user
<username> identified by <password>
2>temporary tablespace
<temp_tablespace_name>
3>default tablespace
<default_tablespace_name>
4>quota unlimited on <default_tablespace_name>;
Statement processed.
SQL>grant connect, resource,
recovery_catalog_owner to <username>;
Statement processed.
Manually transfer the Oracle password file orapw<Oracle SID name> from the
source computer to the destination computer. Usually, this file resides in ORACLE_HOME/dbs.
Export the recovery catalog data for the catalog user.
For example, if the user ID for the
recovery catalog owner is user1, you need to export the database
backup information for user1.
Import the recovery catalog data to the new user account for the
destination computer.
Example using IMPORT CATALOG Command:
RMAN>IMPORT CATALOG user1/user1@src;
Copy the recovery catalog�s connect string entry in the
tnsnames.ora
file from the source host to the destination host.
Make sure that the ORACLE_SID and ORACLE_HOME are appropriately
configured on the destination computer.
Example:
For Unix:
#export ORACLE_SID= <target database SID>
#export ORACLE_HOME= <Oracle home directory>
For Windows:
C:\set ORACLE_SID= <target database SID>
C:\set ORACLE_HOME= <Oracle home directory>
Install the Oracle iDataAgent and configure
it as client
in the same CommServe in which the source computer resides.
Create and configure a new Oracle instance, similar to the one existing
in the source computer on the destination computer. Ensure that this
instance is in NOMOUNT mode.
Restoring the Database
From the CommCell Browser, navigate to Client Computers |
<Client> | Oracle.
Right-click the <Instance> point to All Tasks and then
click Restore.
Select the name of the client computer from the Destination Client
list.
Select Restore Control File check box.
Click Advanced.
Click the Options tab.
If the database is in NOARCHIVELOG mode, then select No Redo Logs.
If the computer on which you hosted a database is damaged or destroyed, you can
restore and recover the lost database on a new host computer with a different directory
structure. You can restore a database either in ARCHIVELOG or NOARCHIVELOG mode
on a new host.
By default, the database is restored in the ARCHIVELOG mode, You can also
choose to restore the db in NOARCHIVELOG mode.
Use the following steps to restore and recover a database to a new host with
a different directory structure:
Prerequisites
Verify the following in both the source and destination computers:
The connection specifications (host, service name, port) in the
tnsnames.ora file on both the source and
destination computers should be different.
The <username> you use for the destination computer is different
than the username for the source computer.
Sufficient disk space is available on the destination computer to
accommodate the restored database.
Both the source and destination computers should have the following
similar features:
Operating systems
Oracle version
ORACLE_SID
init <SID>.ora file
Processor (32-bit or 64-bit)
Datafile directory structures
Configuring the Init <SID>.ora File
Copy the init<SID>.ora from the old host to the new host.
Edit the init<SID>.ora file on the new host to reflect all the directory
structure changes (i.e., change the path for control files, archivelog
destination and *dump destinations).
Create the directory structures as defined in
init<SID>.ora file
for all paths.
Setting up the Source and Destination Hosts
Create a new user account
with recovery catalog owner permission within the Recovery Catalog for the destination computer.
Use a different <username>
Example:
SQL>create user
<username> identified by <password>
2>temporary tablespace
<temp_tablespace_name>
3>default tablespace
<default_tablespace_name>
4>quota unlimited on <default_tablespace_name>;
Statement processed.
SQL>grant connect, resource,
recovery_catalog_owner to <username>;
Statement processed.
Manually transfer the Oracle password file orapw<Oracle SID name> from the
source computer to the destination computer. Usually, this file resides in ORACLE_HOME/dbs.
Export the recovery catalog data for the catalog user.
For example, if the user ID for the
recovery catalog owner is user1, you need to export the database
backup information for user1.
Import the recovery catalog data to the new user account for the
destination computer.
Example using IMPORT CATALOG Command:
RMAN>IMPORT CATALOG user1/user1@src;
Copy the recovery catalog�s connect string entry in the
tnsnames.ora
file from the source host to the destination host.
Make sure that the ORACLE_SID and ORACLE_HOME are appropriately
configured on the destination computer.
Example:
For Unix:
#export ORACLE_SID= <target database SID>
#export ORACLE_HOME= <Oracle home directory>
For Windows:
C:\set ORACLE_SID= <target database SID>
C:\set ORACLE_HOME= <Oracle home directory>
Install the Oracle iDataAgent and configure
it as client
in the same CommServe in which the source computer resides.
Create and configure a new Oracle instance, similar to the one existing
in the source computer on the destination computer. Ensure that this
instance is in NOMOUNT mode.
Restoring the Database
From the CommCell Browser, navigate to Client Computers |
<Client> | Oracle.
Right-click the <Instance> point to All Tasks and then
click Restore.
Select the name of the client computer from the Destination Client
list.
Select Restore Control File check box.
Click Advanced.
Click the Options tab.
If the database is in NOARCHIVELOG mode, then select No Redo Logs.
The point-in-time restore is useful in the following scenarios:
If any undesired transaction occurs in the database, you can revert the
database to a state just before the transaction.
If a database fails, you can restore to the state just before the point
of failure.
When you restore and recover an entire database to a previous point-in-time from an online backup or offline backup (depending on how the subclient
was configured for backups) to the original host, it is recommended to use the
control files.
When you perform a point-in-time restore for a database, the next
scheduled backup for that database will automatically convert to a full
backup.
Use the following steps to restore and recover a database to a previous
point-in-time:
From the CommCell Browser, navigate to Client Computers |
<Client> | Oracle.
Right-click the <Instance>, point to All Tasks
and then click Restore.
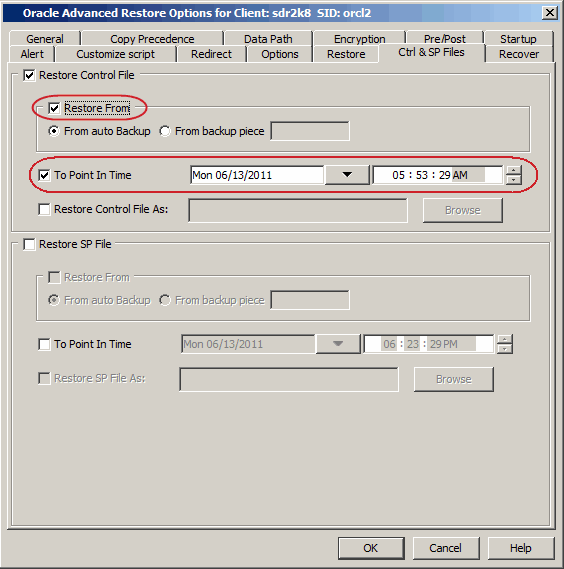
Select Restore Control File check box, if you want to restore
the control file(s).
Click Advanced.
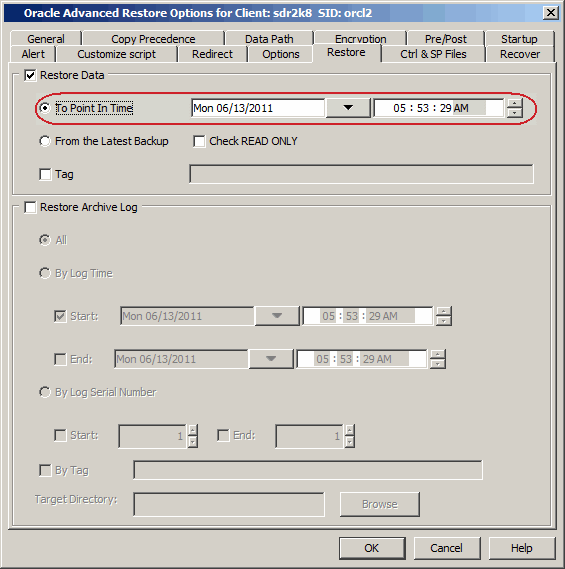
Click the Restore tab.
Click To Point-In-Time and select the data and time.
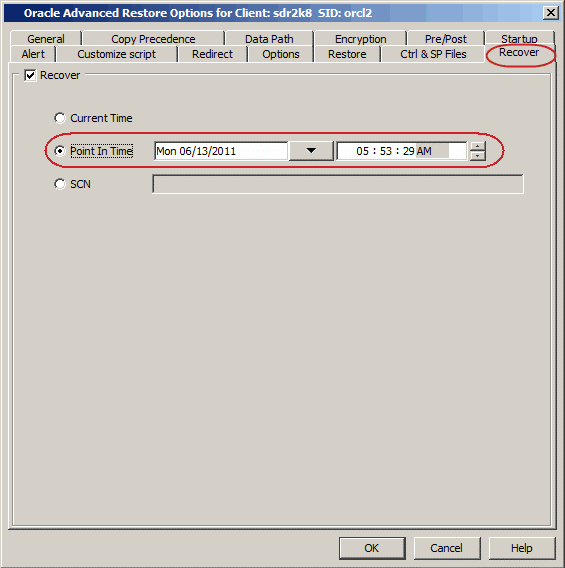
Click the Recover tab.
Click the Point-In-Time and select the data and time.
Click Ctrl&SP Files Tab, if you have selected to restore
the control file(s).
Select Restore From check box.
Click the Point-In-Time and select the data and time.
You must restore the control files to a point-in-time later than
or equal to the point-in-time set in the Restore tab.
In addition to restoring a database, you can also restore specific tablespaces
or datafiles that were lost due to an error or corruption. By default, the
selected tablespaces/datafiles are restored to the original location from the
latest online backup.
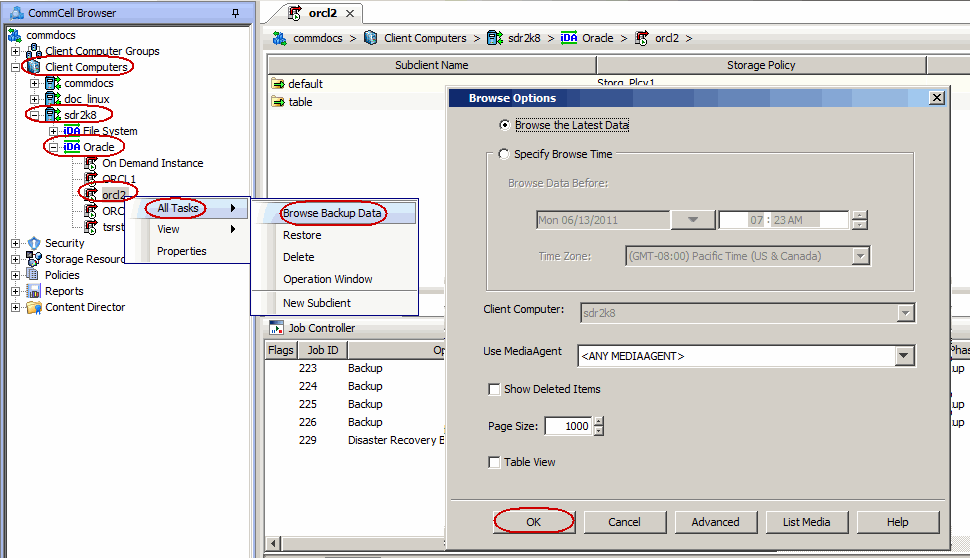
Use the following steps to restore the datafile(s) or tablespace(s):
From the CommCell Browser, navigate to Client Computers |
<Client> | Oracle.
Right-click the <Instance>, point to All Tasks
and then click Browse Backup Data.
Click OK.
In the right pane of the Browse window, select the datafiles
or tablespaces you want to restore and click Recover All Selected.
Click Advanced.
Click the Options tab and select the Switch Database
mode for Restore checkbox.
Click OK.
If you
are restoring system tablespaces, you need to manually switch the
database to mount mode.
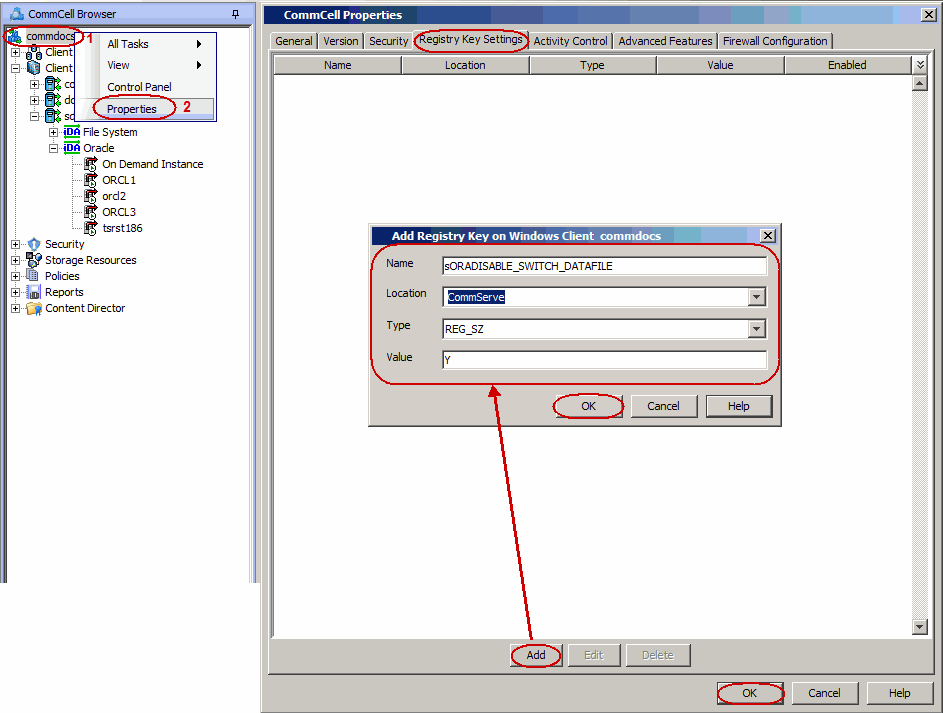
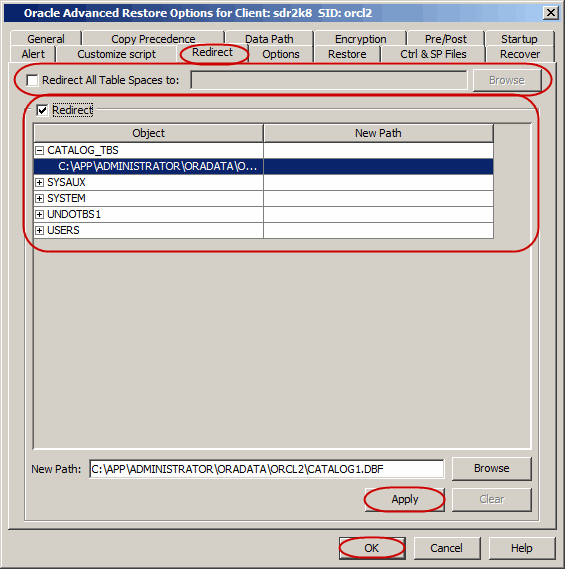
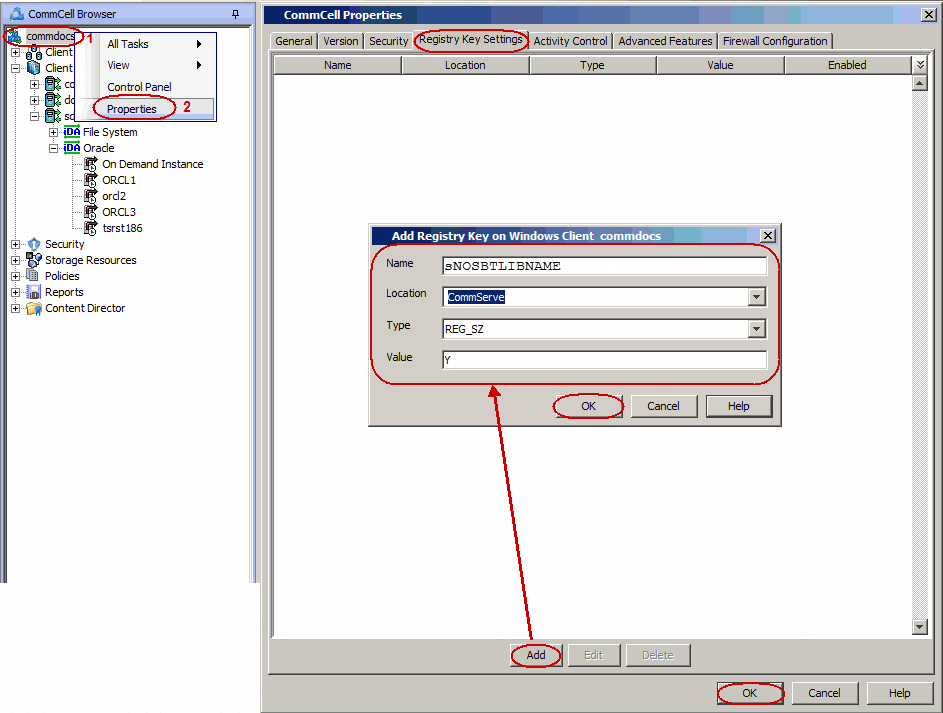
By default, the control file will be automatically updated with the new
location when you redirect tablespaces/datafiles to a new location. Use the
following steps to redirect the tablespaces/datafiles to a new location without
updating the control file:
From the CommCell Browser, right-click the <CommServe>
and then click Properties.
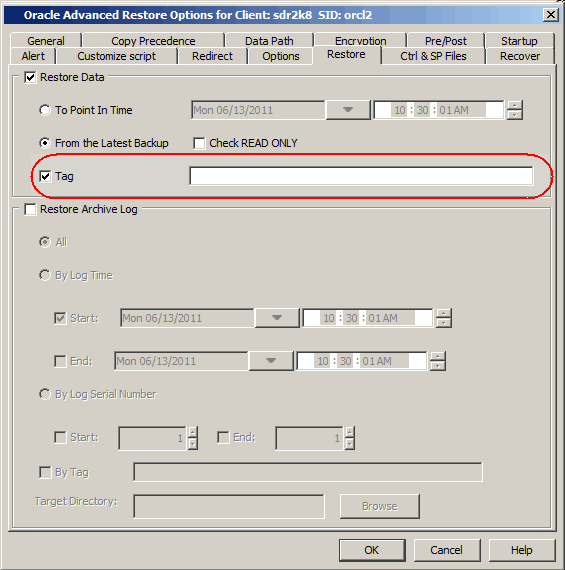
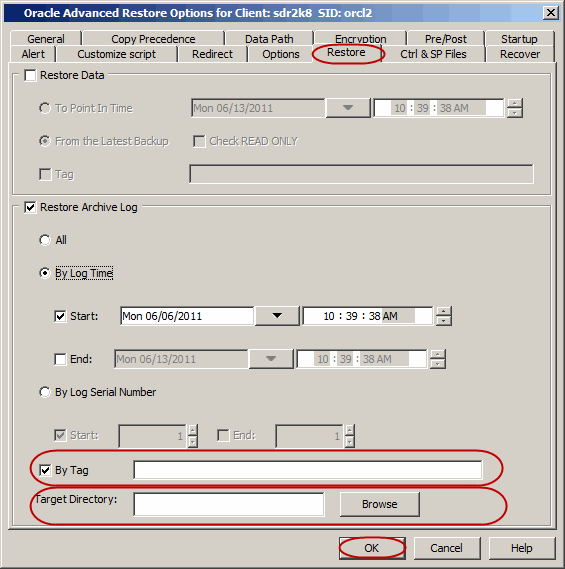
If you have assigned unique identification tags during backups, you can restore
from a specific backup using the tag. Use the following steps to restore the datafile(s) or tablespace(s) using a specific
tag:
From the CommCell Browser, navigate to Client Computers |
<Client> | Oracle.
Right-click the <Instance>, point to All Tasks
and then click Browse Backup Data.
Click OK.
In the right pane of the Browse window, select the datafiles
or tablespaces you want to restore and click Recover All Selected.
Click Advanced.
Click the Restore tab.
Select the Tag check box and type the Oracle Tag name that
is assigned for a specific backup that you want to restore.
Archive logs can be restored separately or along with the database. Archive Log
restores are useful in the following scenarios:
If there is a database failure and you need to recover the database to
the recent state, you will restore all the logs along with the database.
If the logs from a specific time range were lost due to a hard disk
corruption, you can restore them by performing a point-in-time restore of
the logs.
In certain cases, you might need to restore only specific logs
that are missing in the database.
Such logs can be identified and then restored using a serial number or
identification tag.
When you browse between a specific point of time range, the logs pertaining
to all the cycles within the specified time range will be listed.When restoring
the archive logs based on the log time, if the data is also included in the
restore, ensure that the point-in-time range for the restore is the same for
both the data and logs.
If you are including the database in the restore, see point-in-time restore
to restore the database to a specific point-in-time. Use the following steps to restore the logs to a specific log time:
From the CommCell Browser, navigate to Client Computers |
<Client> | Oracle.
Right-click the <Instance>, point to All Tasks
and then click Restore.
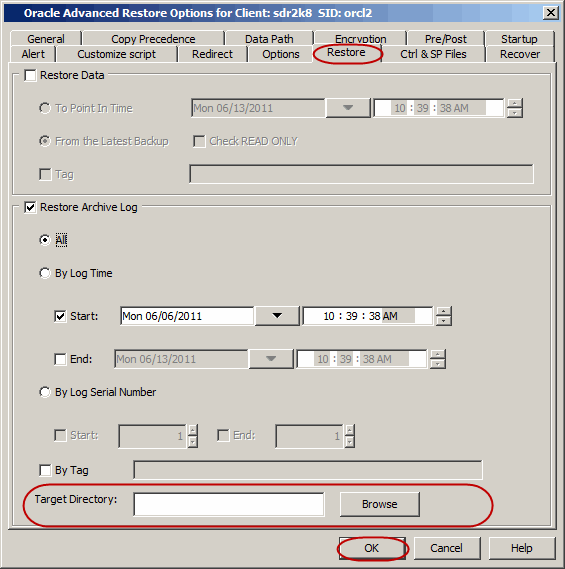
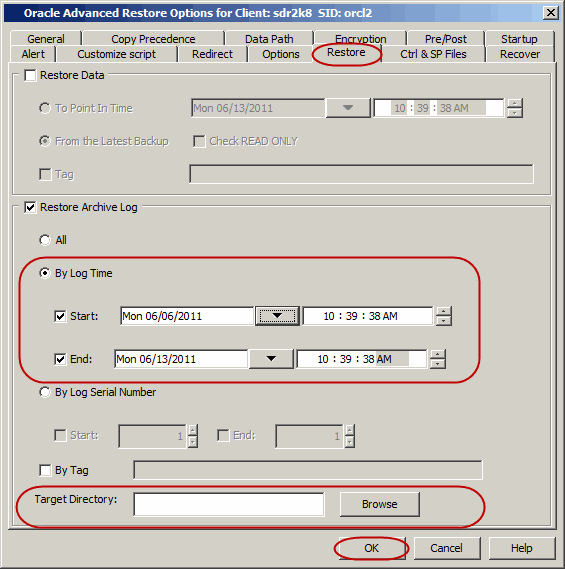
Select the Restore Archive Log check box.
Click Advanced.
Click the Restore tab.
Click By Log Time and specify the point-in-time (date
and time) restore of archived log files.
In the Target Directory box, type the path or click Browse
to specify the path to restore all the logs.
Control and SP files are required to recover a database to the current
state. Restoring a control/sp file is useful in the following scenarios:
If you want to restore the backup repository contained in the control file
when the Control file is lost.
If the recovery catalog is lost.
If the recovery catalog was never used.
If the catalog connect string is not specified for the instance during
the backup.
Ensure that the database is in NOMOUNT mode when you restore the
control/sp files.
The database will be in MOUNT mode after you restore the control/SP
file.
Ensure that you have previously configured auto backup of
control files to restore the control file from auto backup. Restoring a control file will destroy all the previous
backups. Hence, you need to perform a full backup after you restore a control
file.
If the control file and recovery catalog are lost, you can restore the
control file from a specific backup piece using a backup piece number. (Backup
piece references the backup of one or several database files)
You can obtain the backup piece value from the RMAN logs of the
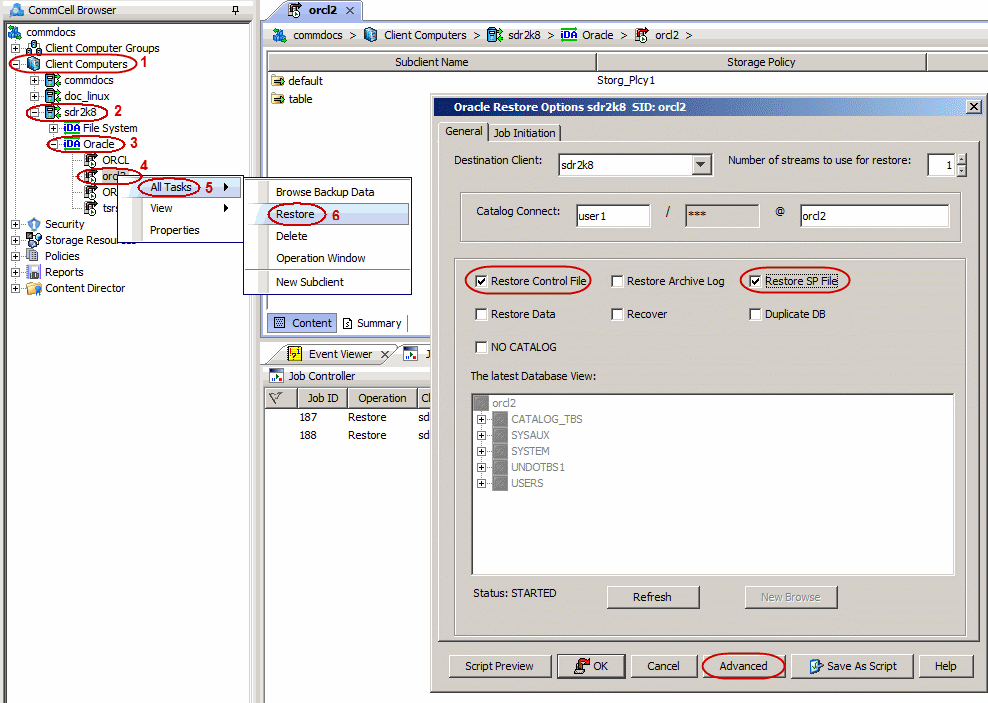
backup job. Use the following steps to restore a control/sp file from a specific backup:
From the CommCell Browser, navigate to Client Computers |
<Client> | Oracle.
Right-click the <Instance>, point to All Tasks
and then click Restore.
Select the Restore Control File and Restore SP File check boxes.
Click Advanced.
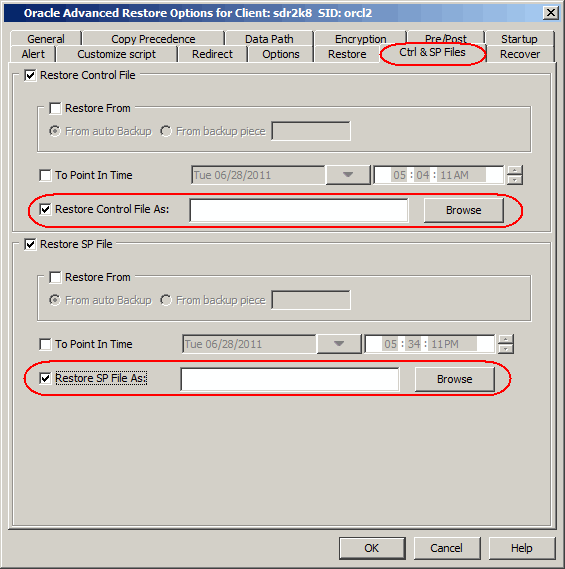
Click the Ctrl&SP Files tab.
Under the Restore Control File, select Restore From check
box.
Click From Backup Piece box and type theBackup
Piece value.
Under the Restore SP File, select Restore From check box.
Click From Backup Piece box and type theBackup
Piece value.
If your database consists of multiple copies of control files, you can replace
a corrupted control file by manually copying from an existing control file and restoring it.
Follow the steps given below to restore a control file from an existing control
files:
Shutdown the database.
SQL> shutdown
Manually copy one of the existing control files to the missing control file
location.
Assign the same owner, group and file permissions to the new control file
as that of the original missing control file.
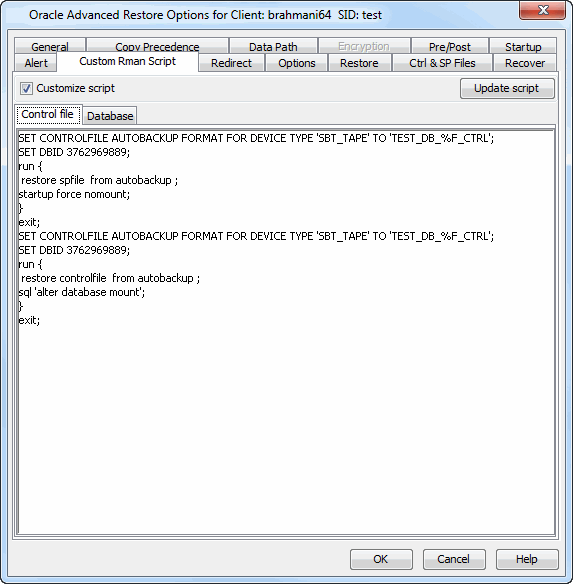
If auto backup format is customized other than the default format( �%F�), you
can customize the RMAN Script to restore the controlfile/spfile from this custom
format auto backup without catalog.
The custom format for auto backup is as follows:
RMAN> show all;
using target database control file instead of recovery catalog
RMAN configuration parameters for database with db_unique_name TEST are:
CONFIGURE RETENTION POLICY TO REDUNDANCY 1; # default
CONFIGURE BACKUP OPTIMIZATION OFF; # default
CONFIGURE DEFAULT DEVICE TYPE TO DISK; # default
CONFIGURE CONTROLFILE AUTOBACKUP ON;
CONFIGURE CONTROLFILE AUTOBACKUP FORMAT FOR DEVICE TYPE DISK TO 'TEST_DB_%F';
CONFIGURE CONTROLFILE AUTOBACKUP FORMAT FOR DEVICE TYPE 'SBT_TAPE' TO 'TEST_DB_%F_CTRL';
CONFIGURE DEVICE TYPE DISK PARALLELISM 1 BACKUP TYPE TO BACKUPSET; # default
CONFIGURE DATAFILE BACKUP COPIES FOR DEVICE TYPE DISK TO 1; # default
CONFIGURE ARCHCONFIGURE ARCHIVELOG BACKUP COPIES FOR DEVICE TYPE DISK TO 1; # default
From the CommCell Browser, navigate to Client Computers |
<Client> | Oracle.
Right-click the <Instance>, and select Restore.
Click Advanced.
Click the Customize Script tab.
Select the Customize Script checkbox.
The default control file/spfile
restore script will be generated in Control File tab.
Edit the control file/spfile restore script:
Example:
SET CONTROLFILE AUTOBACKUP FORMAT FOR DEVICE TYPE 'SBT_TAPE'
TO 'TEST_DB_%F_CTRL';
SET DBID 3762969889;
run {
restore spfile from autobackup ;
startup force nomount;
}
exit;
SET CONTROLFILE AUTOBACKUP FORMAT FOR DEVICE TYPE 'SBT_TAPE' TO 'TEST_DB_%F_CTRL';
SET DBID 3762969889;
run {
restore controlfile from autobackup ;
sql 'alter database mount';
}
exit;
Click OK.
Restoring Container and Pluggable databases
Oracle 12c supports container and pluggable databases.
Calypso supports the restore of container
and pluggable databases.
If you have backed up an entire container database you can restore the entire
container database, a single pluggable database, or multiple pluggable
databases.
Restoring pluggable databases from a
container database backup
1.
Before running the restore, enter the following on the command line:
alter pluggable database <PDB_NAME> close;
2.
Create and
customize
an RMAN script file on the client computer, where the last line in the
script specifies the pluggable databases to restore. The line has
the following format, with "pluggable_database_name1" through "pluggable_databaseN". Each database must be
separated by a "," and must be part of the backup.
restoring pluggable databases from a
pluggable backup
1.
Before running the restore, enter the following on the command line:
alter pluggable database <PDB_NAME> close;
2.
Create and
customize
an RMAN script file on the client computer where the last line in the
script specifies the pluggable database to restore. The line has
the following format, with "pluggable_database_name1" through "pluggable_databaseN". Each database must be
separated by a "," and must be part of the backup.
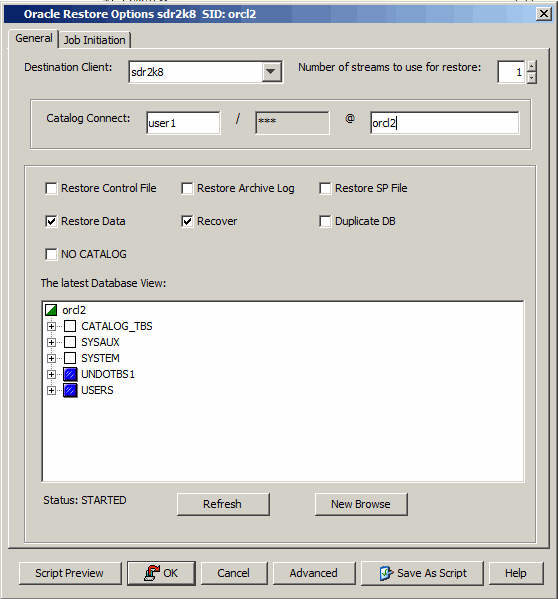
By default, the database is recovered along with the restore. However, you
can also restore the data and then recover the database at a later
point-in-time.
You can recover a database to the current time either to the original host or
to a different host. Use the following steps to recover a database to the current
time:
From the CommCell Browser, navigate to Client Computers |
<Client> | Oracle.
Right-click the <Instance>, point to All Tasks
and then click Restore.
You can apply archived logs and recover a database to a previous
point-in-time where it is consistent and stable. Use the following steps to recover a
database to a point-in-time:
From the CommCell Browser, navigate to Client Computers |
<Client> | Oracle.
Right-click the <Instance>, point to All Tasks
and then click Restore.
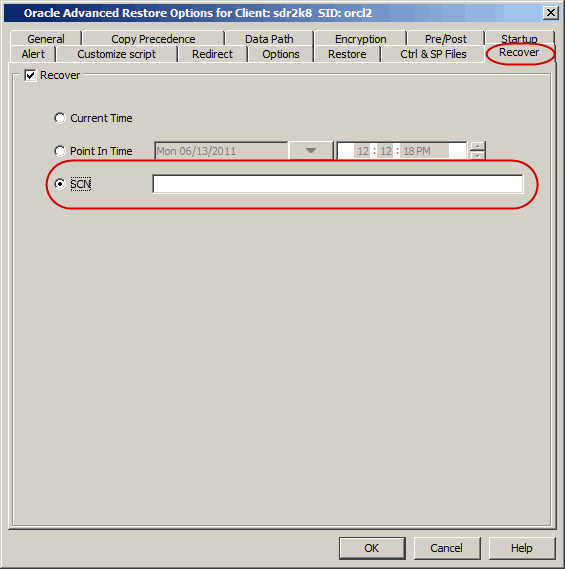
The System Change Number (SCN) keeps track of the timing of transactions in
the oracle
database. The SCN's are stored in the control files and the datafile headers.
You can recover the database to the last existing SCN number in the control file.
(The last SCN number denotes the last consistent state of the database.)
Use the following steps to recover a database using SCN:
From the CommCell Browser, navigate to Client Computers |
<Client> | Oracle.
Right-click the <Instance>, point to All Tasks
and then click Restore.
A duplicate (auxiliary) database is a copy or subset of the target database and has a unique DBID. It is independent of the primary database and can be registered in the same
recovery catalog as the primary database. The duplicate database will be useful
for testing and demo purposes.
If the duplicate (auxiliary) database already exists
in the destination computer, it will be overwritten. Duplicate database is
created from the full backup of the database with the logs. If you want the
latest data in the duplicate database, make sure to perform a full backup with
the log files before creating the duplicate database.
Use the following steps to create a duplicate database on a different host
with the configured instance. Make sure that the instance is configured on a
different host in the CommCell Console.
Perform a full backup
along with the log files on the original database.
On the destination host, make sure to remove the temp.dbf file from
the existing database instance.
Manually, copy the init<SID>.ora file from the source computer
to the destination computer.
On Unix:
$ORACLE_HOME
On Windows:
%ORACLE_HOME%
Update the database name, dump files, archive logs and the
control file locations in the init<SID>.ora file for the duplicate
database instance.
Add the DB_FILE_NAME_CONVERT and LOG_FILE_NAME_CONVERT parameters
in the init<SID>.ora file. These parameters will redirect the datafiles, temp files, and log files to the auxiliary instance.
Make sure that all the other parameters in the
init<SID>.ora file are same as that
in the original database.
(When using these parameters on a Windows computer, the file paths should
be entered in uppercase.)
On Windows clients, restart Oracle services.
Skip this step,
if you are using an Unix client.
Add the duplicate database instance name in the Listener.ora
file on the destination host and add TNS entry on Tnsnames.ora files
on the source and destination hosts.
Add the source database name in the Tnsnames.ora
file on the destination host.
In order to create duplicate database on a different host without a
configured instance, we need the following installed on the destination
computer:
Base client
Oracle iDataAgent
Use the following steps to create a duplicate database on a different host
without the configured instance. Make sure that the duplicate instance is not
configured from the CommCell console.
Perform a full backup
along with the log files on the original database.
Create a duplicate database instance on the destination host.
Manually, copy the init<SID>.ora file from the source computer
to the destination computer.
On Unix:
$ORACLE_HOME
On Windows:
%ORACLE_HOME%
Update the database name, dump files, archive logs and the
control file locations in the init<SID>.ora file for the duplicate
database instance.
Add the DB_FILE_NAME_CONVERT and LOG_FILE_NAME_CONVERT
parameters in the init<SID>.ora file. These parameters will redirect
the datafiles, temp files, and log files to the auxiliary instance.
Make sure that all the other parameters in the
init<SID>.ora file are same as that
in the original database. Copy the destination computer
init<SID>.ora to
source computer.
(When using these parameters on a Windows computer, the file paths should
be entered in uppercase.)
On Windows clients, restart Oracle services.
Skip this step,
if you are using an Unix client.
Make sure that Static listener is configured on the destination
host. Add the duplicate database instance name in the Listener.ora
file on the destination host.
Add the TNS entry in Tnsnames.ora
file on the destination host.
Add the auxiliary database name in the Tnsnames.ora file on the
source host. Make sure to use the password
change_on_install
when you create the password file for auxiliary database.
Provide a valid connect string for the auxiliary channel.
Example:
sys/sys@<SID name>
Startup the duplicate database instance in NOMOUNT mode.
When using a different host without configuring an instance, the install path in the source and destination clients
must be the same. Use the following steps to set the same install path
in the source and destination clients.
From the CommCell Browser, right-click the <CommServe>
and then click Properties.
Use the following steps to create a duplicate database on the same host
without the configured instance:
Perform a full backup
along with the log files on the original database.
Create a duplicate database instance on the destination host. If
the database already exists on the destination host, make sure to remove
the temp.dbf file before performing a restore operation.
Manually, copy the init<SID>.ora file from the source computer
to the destination computer.
On Unix:
$ORACLE_HOME
On Windows:
%ORACLE_HOME%
Update the database name, dump files, archive logs and the
control file locations in the init<SID>.ora file for the duplicate
database instance.
Add the DB_FILE_NAME_CONVERT and LOG_FILE_NAME_CONVERT
parameters in the init<SID>.ora file. These parameters will redirect
the datafiles, temp files, and log files to the auxiliary instance.
Make sure that all the other parameters in the
init<SID>.ora file are same as that
in the original database.
Use the following steps to create a duplicate database on the same host with
the configured instance:
Perform a full backup
along with the log files on the original database.
Create a duplicate database instance on the destination host. If
the database already exists on the destination host, make sure to remove
the temp.dbf file before performing a restore operation.
Manually, copy the init<SID>.ora file from the source computer
to the destination computer.
On Unix:
$ORACLE_HOME
On Windows:
%ORACLE_HOME%
Update the database name, dump files, archive logs and the
control file locations in the init<SID>.ora file for the duplicate
database instance.
Add the DB_FILE_NAME_CONVERT and LOG_FILE_NAME_CONVERT
parameters in the init<SID>.ora file. These parameters will redirect
the datafiles, temp files, and log files to the auxiliary instance.
Make sure that all the other parameters in the
init<SID>.ora file are same as that
in the original database.
By default, the read only tablespaces are not verified for consistency and
are restored from the backup. You can skip the consistent tablespaces and restore the tablespaces that
are not consistent or missing. This will save the time taken for the restore.
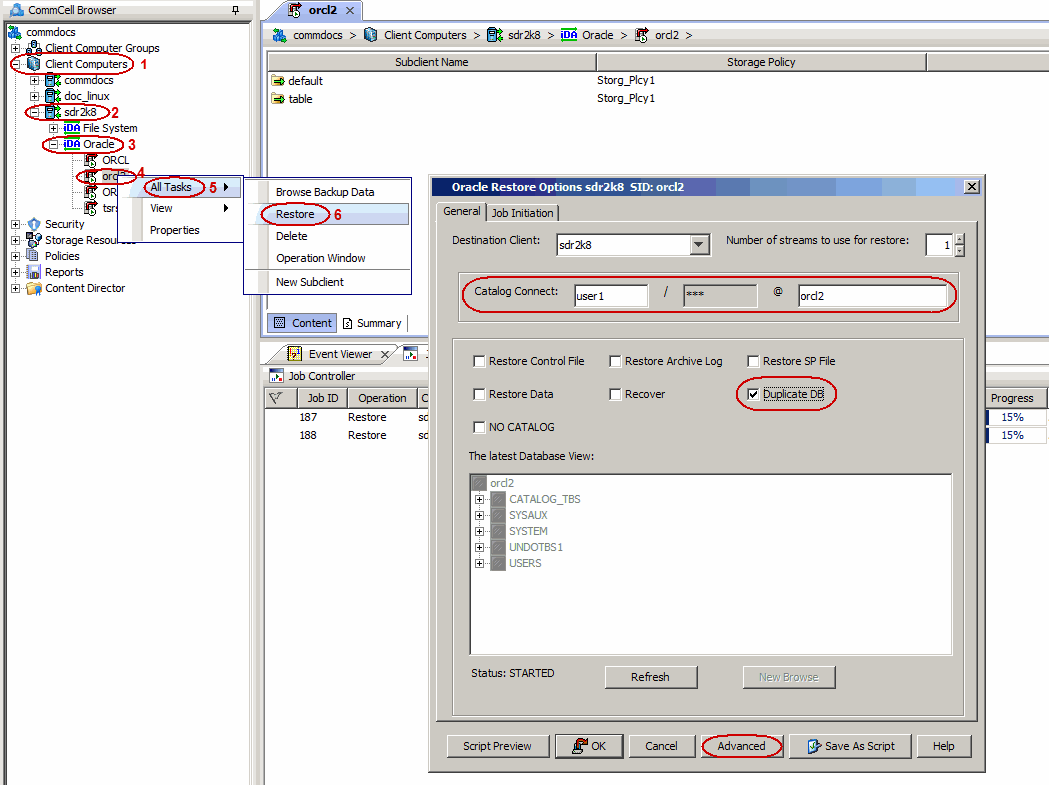
Use the following steps to exclude read only table spaces during restore:
From the CommCell Browser, navigate to Client Computers |
<Client> | Oracle.
Right-click the <Instance>, point to All Tasks
and then click Restore.
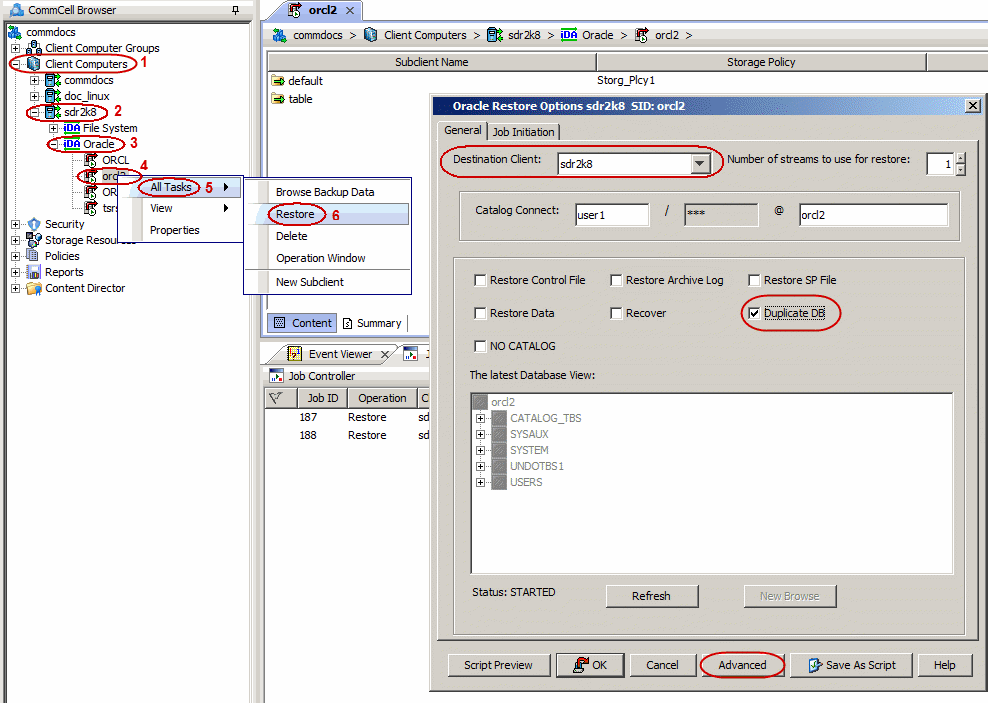
Select the name of the client computer from the Destination Client
list.
Select Duplicate DB check box.
Click Advanced.
Click Duplicate tab.
Click Duplicate To.
Type the name of duplicate database in Database Name box.
Type the name of startup Parameter file in Pfile box or click
Browse to locate it.
By default, a duplicated database is
opened without any restricted access. If necessary, you can open the db in restricted mode for
administrative tasks. This will restrict access to other users.
Use the following steps to open the duplicate database in restricted
mode:
From the CommCell Browser, navigate to Client Computers |
<Client> | Oracle.
Right-click the <Instance>, point to All Tasks
and then click Restore.
Select the name of the client computer from the Destination Client
list.
Select Duplicate DB check box.
Click Advanced.
Click Duplicate tab.
Click Duplicate To.
Type the name of duplicate database in Database Name box.
Type the name of startup Parameter file in Pfile box or click
Browse to locate it.
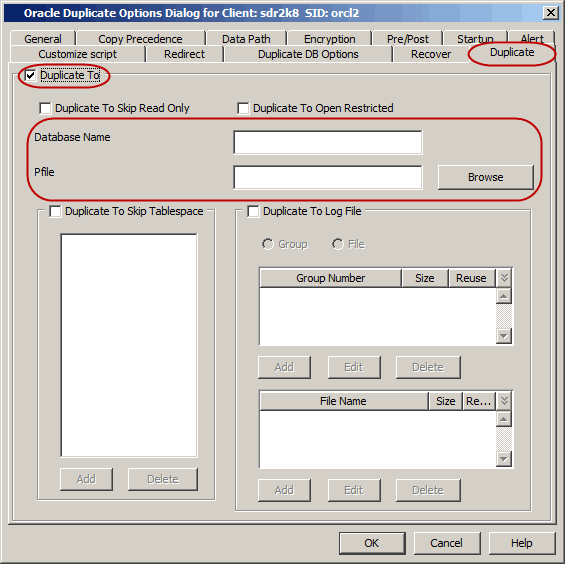
While creating a duplicate database, you can exclude some tablespaces from
the duplicate database. Use the following steps to exclude the tablespaces from the duplicate database:
From the CommCell Browser, navigate to Client Computers |
<Client> | Oracle.
Right-click the <Instance>, point to All Tasks
and then click Restore.
Select the name of the client computer from the Destination Client
list.
Select Duplicate DB check box.
Click Advanced.
Click Duplicate tab.
Click Duplicate To.
Type the name of duplicate database in Database Name box.
Type the name of startup Parameter file in Pfile box or click
Browse to locate it.
Select the Duplicate To Skip TableSpaces check box.
Click Add
Select the tablespaces that appear in the
TableSpaces box to exclude from the duplicate database.
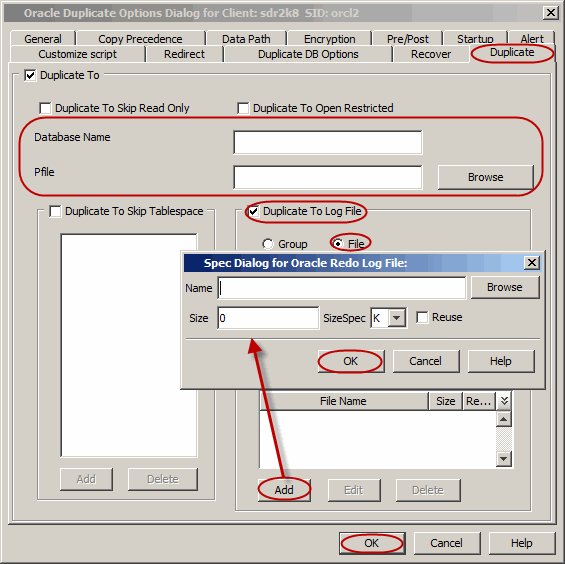
You can create online redo logs for duplicate database and apply them to
restore the database in case of corruption. Use the following
steps to create an online redo log file:
From the CommCell Browser, navigate to Client Computers |
<Client> | Oracle.
Right-click the <Instance>, point to All Tasks
and then click Restore.
Select the name of the client computer from the Destination Client
list.
Select Duplicate DB check box.
Click Advanced.
Click Duplicate tab.
Click Duplicate To.
Type the name of duplicate database in Database Name box.
Type the name of startup Parameter file in Pfile box or click
Browse to locate it.
Select Duplicate To Log File check box.
Click File to select a file containing the online redo log.
Click Add to include the specifications for an online redo
log file.
In the Spec Dialog for Oracle Redo Log File box, type the
name or click Browse to select the redo log file.
Type the Size of the online redo log file.
Select the Size Specifications of the file from SizeSpec
list.
Select Reuse check box to allow the database to reuse an
existing file.
By default, groups are created to include specific online redo log members. Use the following steps to add specifications for
each of these online
redo log groups:
From the CommCell Browser, navigate to Client Computers |
<Client> | Oracle.
Right-click the <Instance>, point to All Tasks
and then click Restore.
Select the name of the client computer from the Destination Client
list.
Select Duplicate DB check box.
Click Advanced.
Click Duplicate tab.
Click Duplicate To.
Type the name of duplicate database in Database Name box.
Type the name of startup Parameter file in Pfile box or click
Browse to locate it.
Select Duplicate To Log File check box.
Click Group to select a group containing the online redo
log members.
Click Add.
In the Spec Dialog for Oracle Redo Log Group box, add the
Size of the Group.
Select the Size Specifications from SizeSpec list.
Select Reuse check box to allow the database to reuse an
existing file.
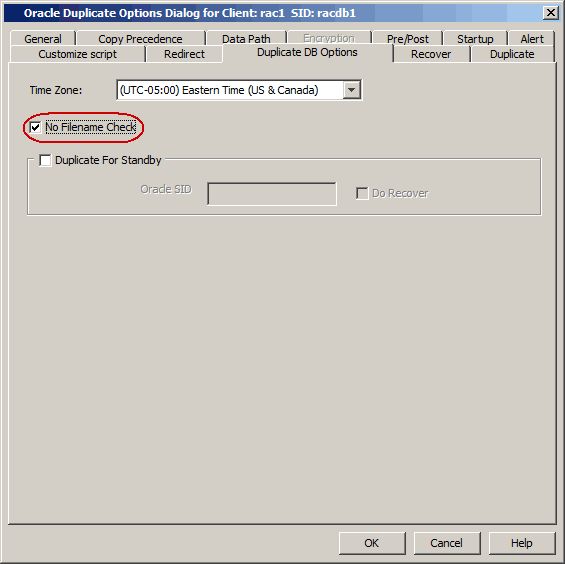
By default, when you create a standby database, RMAN will verify the target
datafiles for duplicate files (files sharing the same names). This verification
job may consume more time. Hence, use the following
steps to prevent RMAN from performing this verification:
From the CommCell Browser, navigate to Client Computers |
<Client> | Oracle.
Right-click the <Instance>, point to All Tasks
and then click Restore.
Type the connect string name in the Catalog String box.
Standby databases are useful when a primary database experiences a disaster
such as hardware related failure or data corruption and it is not configured for
a cluster failover. A standby database is a replicated copy of the primary database.
It is updated by applying archived redo logs from the primary database. A
standby database will not have a unique DBID.
Create an initialization parameter file,
init<standbydb>.ora for the standby
database and set the following initialization parameters on the standby
host:
Ensure to run the Ora_install.sh
on the auxiliary client.
Install the Oracle iDataAgent
on the Destination host.
Set the Standby Role Initialization parameter,
DB_FILE_NAME_CONVERT,to add all the
temp datafiles from the primary database location to the standby database
location.
From the CommCell Browser, navigate to Client Computers |
<Client> | Oracle.
Right-click the <Instance>, point to All Tasks
and then click Restore.
Type the connect string name in the Catalog String box.
Select Duplicate DB check box.
Click Advanced.
Click Duplicate DB Options tab.
Click Duplicate For Standby.
Type the Oracle <SID> name in Oracle SID box.
Click OK.
Once the job is completed, the new database will be on MOUNT
mode for the standby database. You must enable the log shipping to
maintain the standby database up-to-date.
Alter database recover managed standby
database disconnect;
Use the following steps to create a standby database on a different host with
the configured instance:
Setting up a Standby database:
Perform an online full backup with current control file.
Set the following initialization parameters in the primary initialization
parameter file init<standbydb>.ora (i.e.,
Startup PFile) on source (primary) host.
Use a connect string to connect to the auxiliary database when the
instance is not configured. Make sure to use the password
change_on_install
when you create the password file for auxiliary channel while creating
password file for standby database on destination host.
Startup the standby database instance in NOMOUNT mode. Configure
the Oracle instance for the destination host in the CommCell Browser.
Ensure to run the Ora_install.sh
on the auxiliary client.
Ensure that the Oracle iDataAgent
is installed on the Destination host.
Ensure that you set the Standby Role Initialization parameter,
DB_FILE_NAME_CONVERT,to add all the
temp datafiles from the primary database location to the standby database
location.
By default, the database tables can be restored from an online full backup,
provided the table browse was enabled in the associated subclient before
performing the backup. See
Enabling Table Browse
for Restores for
information on configuring the subclient for table browse.
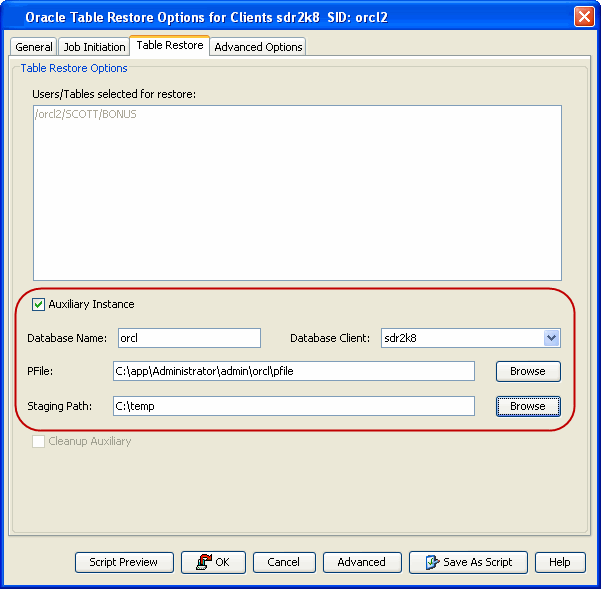
When restoring database tables, by default an auxiliary instance is
automatically created. Hence, make sure that there is enough disk space
on the client for the auxiliary instance.
When restoring the tables to a different host, ensure the following:
Both the source and the destination host should have the same database
schema.
Add the duplicate database instance name in the
Listener.ora file on the destination host and
Tnsnames.ora files on the destination and
source hosts. ,
Add the source database name in the
Tnsnames.ora file on the destination host.
Ensure that both the source and destination clients use a different
connection name in the tnsnames.ora
file.
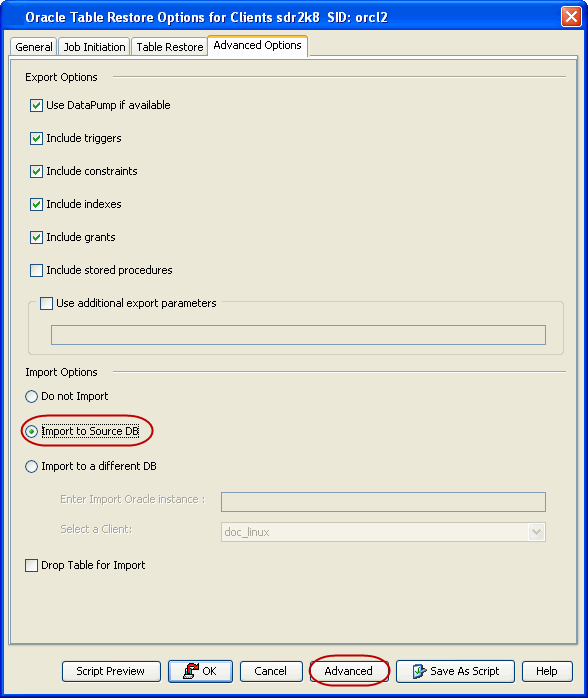
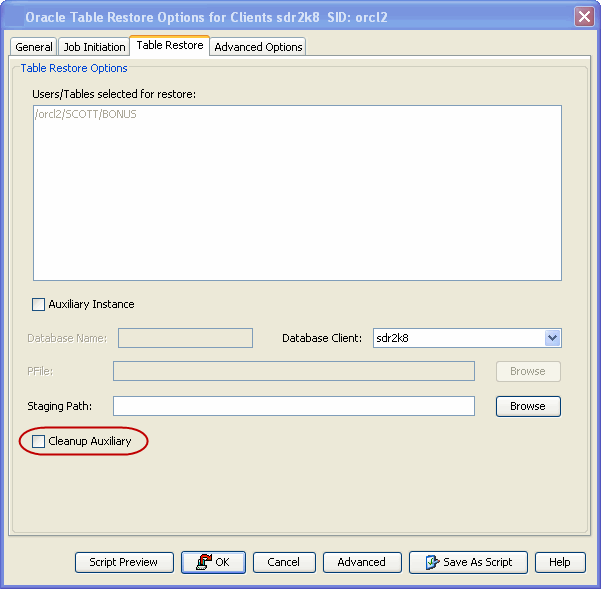
When the selected database client is not the source on a Table Restore, you must select the Auxiliary Instance and provide a user defined Auxiliary database name. If you do not do this, the Auxiliary database is created on source client itself and the selected database client is ignored.
By default, when you restore database tables to a target instance, the
system automatically duplicates the source database to an auxiliary
instance in a temporary staging location specified during the restore
operation. The database will be automatically imported from this
auxiliary instance after the restore.
Use the following steps to set up a specific database as an auxiliary
instance. This is useful when you want to restore a table to a specific
failure point.
1.
Copy the init<SID>.ora file from the
source database to the auxiliary database instance.
2.
Update the database name and the database file locations in the
init<SID>.ora file for the auxiliary database instance.
3.
Add the DB_FILE_NAME_CONVERT and LOG_FILE_NAME_CONVERT
parameters in the
init<SID>.ora file. These parameters will redirect the datafiles,
temp files, and log files to the auxiliary instance.
Add the log_archive_dest_1
parameter is added to the init<SID>.ora file
on the auxiliary instance.
5.
Restart the Oracle Services, if using Windows clients.
6.
Add the destination instance name in the
Listener.ora and Tnsnames.ora files.
If using a different host, add the duplicate database instance name in the
Listener.ora file on the destination host
and Tnsnames.ora files on the destination
and source hosts. Also, add the original database name in the Tnsnames.ora
file on the destination host.
By default, when you restore database tables to a target instance, the
system automatically duplicates the source database to an auxiliary
instance in the specified temporary staging location. Once the database
is duplicated, you can import the tables to the target instance.
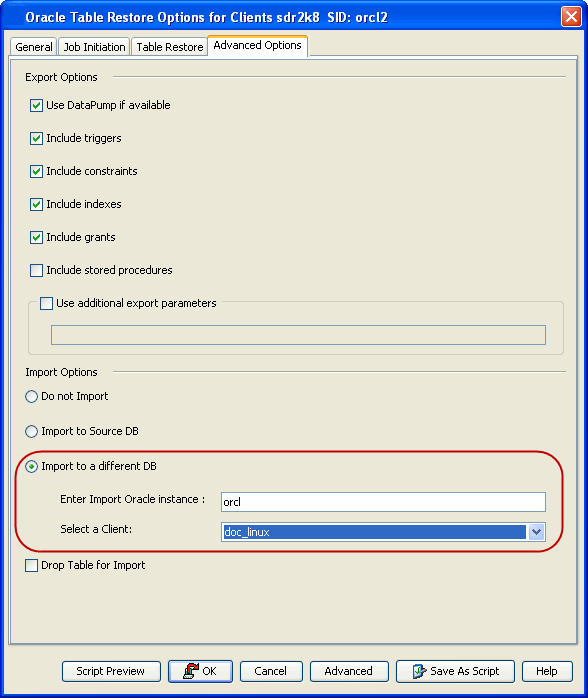
However, if required, you can also use an user-defined auxiliary
instance for the restore operation. This is used when you want to
restore a table to a specific failure point.
When restoring tables to a different host, if a
user-defined auxiliary instance option is selected for the restore, you
need to recover the database to a specified point-in-time or SCN number.
You cannot recover the database to the current time using an
user-defined auxiliary instance.
Setting Up the Auxiliary Instance
1.
Copy the init<SID>.ora file from the
source database to the auxiliary database instance.
2.
Update the database name and the database file locations in the
init<SID>.ora file for the auxiliary database instance.
3.
Add the DB_FILE_NAME_CONVERT and LOG_FILE_NAME_CONVERT parameters in the
init<SID>.ora file. These parameters will redirect the datafiles,
temp files, and log files to the auxiliary instance.
Add the log_archive_dest_1
parameter is added to the init<SID>.ora file
on the auxiliary instance.
5.
Restart the Oracle Services, if using Windows clients.
6.
Add the destination instance name in the
Listener.ora and Tnsnames.ora files.
If using a different host, add the duplicate database instance name in the
Listener.ora file on the destination host
and Tnsnames.ora files on the destination
and source hosts. Also, add the original database name in the Tnsnames.ora
file on the destination host.
In the Location box, select or type
OracleAgent from the list.
In the Type box, select Value.
In the Value box, set the database's characterset as per your database's
characterset and then click OK.
For example, if the database�s nls characterset value is ZHS16GBK, you
can set NLS_LANG reg key to AMERICAN_AMERICA.ZHS16GBK. By default this value
is set to AMERICAN_AMERICA.US7ASCII.
During table restores, the tables are exported from the auxiliary instance to
the destination client and later imported to the target database. By default,
the following data objects are exported along with the tables:
Triggers
Constraints
Indexes
Grants
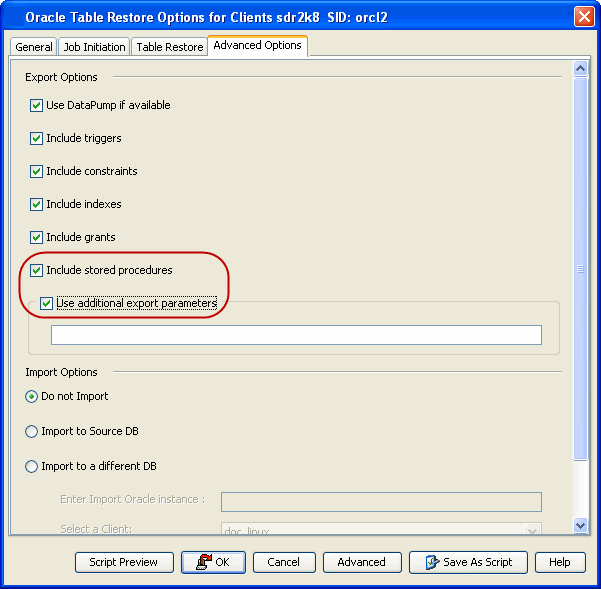
However, the stored procedures associated with the selected tables are not
exported by default. Use the following steps to export the stored procedures and
additional export parameters, such as (COMPRESS or PARALLEL):
Stored procedures are restored from the Schema level. Schema is the
collection of data objects created by the user to contain or reference their
data. Hence, if one of the table within the schema is selected for restore, all
the stored procedures for that schema will also get restored.
When exporting the tables, the datapump export utility is used if it is
supported by the Oracle application. The datapump utility facilitates the export
of stored procedures. In oracle versions that do not support datapump export
utility, you will not be able to include stored procedures during export.
From the CommCell Browser, navigate to Client Computers |
<Client> | Oracle.
Right-click the <Instance>, point to All Tasks and select
Browse Backup Data.
Select the Table View check box and click OK.
From the Browse window, navigate and select the tables to be
restored and click Recover All Selected.
Click the Table Restore tab.
In the Staging Path box, type the location where the auxiliary
instance will be restored.
Click the Advanced Options tab.
Select the Include Stored Procedures checkbox.
Select Use additional export parameters checkbox and type the
parameters to be exported.
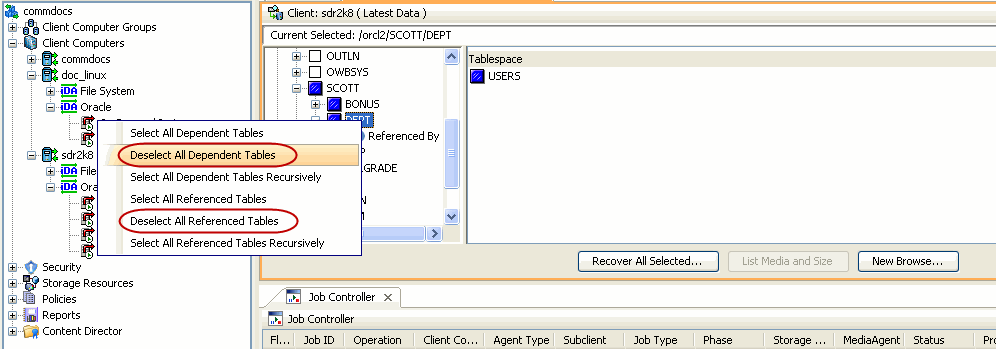
When you browse using the table view, you can also view
the dependent and referenced tables associated with the tables selected for the restore.
Dependent tables are the parent tables (containing the primary key) that the
selected table (containing the foreign key) depends upon. Similarly, Referenced
tables are the child tables (containing the foreign key) that references the
selected table (containing the primary key).
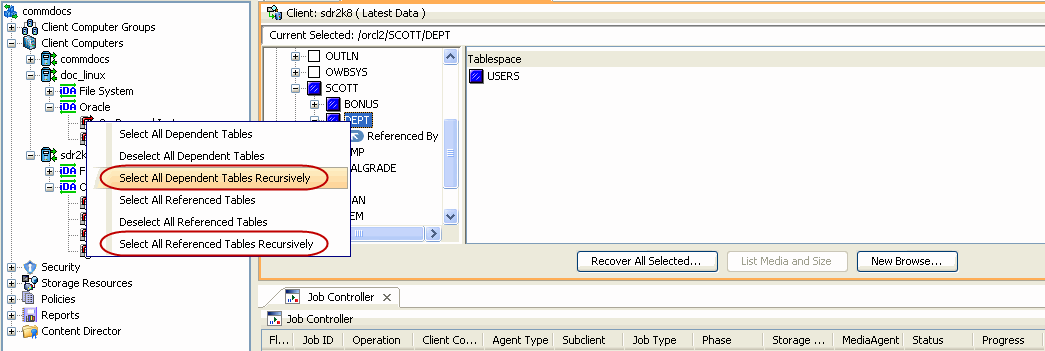
By default, all the dependent and referenced tables will be included in the
restore operation. Use the following steps to exclude the dependent/referenced
tables:
From the CommCell Browser, navigate to Client Computers |
<Client> | Oracle.
Right-click the <Instance>, point to All Tasks and select
Browse Backup Data.
Select the Table View check box and click OK.
From the Browse window, navigate to the table to be restored.
Right-click the <table> and click Select/Deselect All
Dependent Tables to exclude all the dependent tables.
Similarly, click
Deselect All Referenced Tables to exclude all the referenced tables.
Click Restore All Selected.
Click the Table Restore tab.
In the Staging Path box, type the location where the auxiliary
instance will be restored.
By default, the restore operation will overwrite the existing tables in the
destination database during the restore. You can also configure the restore
operation to delete the existing tables before performing the restore.
Manually drop/delete the existing tables at the destination instance and then
import the tables.
Use the following steps to automatically delete existing tables on the
destination instance during restore. Note that you can also manually drop/delete
the existing tables at the destination instance and perform the restore without
enabling this option.
From the CommCell Browser, navigate to Client Computers |
<Client> | Oracle.
Right-click the <Instance>, point to All Tasks and select
Browse Backup Data.
Select the Table View check box and click OK.
From the Browse window, navigate and select the tables to be
restored and click Recover All Selected.
Click the Table Restore tab.
In the Staging Path box, type the location where the tables will
be restored.
You can perform restores of one of more databases from the command line
interface.
Command line restores enable you to perform restore operations on multiple
clients at the same time. It also allows you to reuse the command line scripts
for additional restores.
When performing command line restores, note that backups taken from the
CommCell Console can be restored using Command Line and vice versa. However,
backups taken from a previous version of the CommCell Console can be restored
only from the Command Line.
In order to run the restores from command line, you need an input xml file
which contains the parameters for configuring the restore options. This input
xml file can be obtained using one of the following ways:
Download the
input xml file template and save it on the computer from where the
restore will be performed.
Generate the input xml file from the CommCell Console and save it on the
computer from where the restore will be performed.
You can also submit RMAN scripts from the Command Line Interface using
Qcommands. The RMAN scripts are submitted through argument files. This method
enables you to take advantage of the CommServe's job management and reporting
capabilities as well as media reservation, multi-streaming and storage policies.
When you submit RMAN scripts using qcommands:
One job ID is used in the CommServe. The same Job ID is also used across
different streams and attempts.
The job can be resumed from the point of failure from the CommCell
Console or Command Line.
The job history can be viewed for these jobs.
A list of media can be obtained for the job in primary or secondary
copy.
Job-based storage policies can be used.
Multiple streams can be allocated before the job starts.
The job will use as many available drives and start other streams as
drives become available.
Run time reservation of storage policy can be used during restore. For
example, if a log backup is encountered in the data phase, all data storage
policy resources will be released, and archive log resources will be
dynamically reserved.
1.
Create the RMAN Script file for the restore operation.
Ensure that you
create separate RMAN scripts for the data and logs
run {
allocate channel ch1 type 'sbt_tape'
PARMS="BLKSIZE=262144" ;
allocate channel ch2 type 'sbt_tape'
PARMS="BLKSIZE=262144" ;
restore database ;
recover database;
sql "alter database open";
}
2.
Create the argument file.
For example,
[oraclerestorescript]
/rman_restore.scr
3.
Login to the Commserve from the command prompt.
For example:
qlogin -cs server1 -u user1
4.
Run the qoperation restore command.
Example:
qoperation restore -sc client1 -a
Q_ORACLE -i instance1 -af /argfile2.txt
Name of the file that contains RMAN script for restore.
[rmanlogfile]
[rmanlogfile]
<ouputfile location>/<outputfile name>
Example:
[rmanlogfile]
/usr/temp1
Here, temp1 is the directory and not the file name.
This is an optional parameter.
Location where the RMAN
restore output file will be saved and the name of the
output file.
By default, an output file restore.out is created in the job
results directory. You can change the name of the output file as well as the
location using this parameter. In order to include the JOB ID in the output
file name, you need to set the
sQcmd_Rst_RmanLogFile registry key.
[options]
QR_DO_NOT_USE_ORA_CONNECT_STRING
This is an optional parameter.
If
specified, the restore operation will use the user defined connect string and catalog
connect values specified in the RMAN script will be used instead of the
values specified in the Instance Properties (Details) tab in the CommCell Console.
[mediaagent]
[mediaagent]
<mediaagentname>
Example:
[mediaagent]
MA1
This is an optional parameter.
Name of the MediaAgent to be used for the restore job.
[library]
[library]
<libraryname>
Example:
[library]
LN1
This is an optional parameter.
Name of the library to be used for the restore job.
[drivepool]
[drivepool]
<library_name>/<drivepool_name>
Example:
[drivepool]
LN1/DP1
This is an optional parameter.
Name of the drivepool in the library to be used for the restore job.
[scratchpool]
[scratchpool]
<library_name>/<scratchpool_name>
Example:
[scratchpool]
LN1/SN1
This is an optional parameter.
Name of the scratchpool in the library to be used for the restore job.
The drivepool and scratchpool parameters are applicable only if a tape
library is used for the RMAN backup. The drivepool and scratchpool names
can be given along with the library name followed by a backslash (/) or
itself alone.
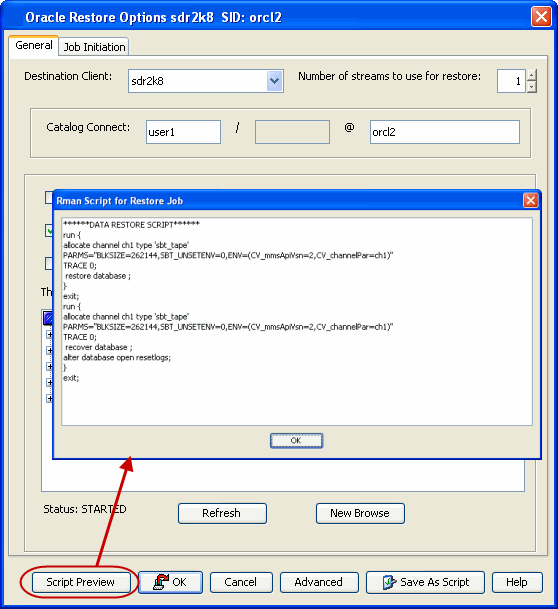
Prior to running a restore operation from the CommCell Console, you can
preview the corresponding RMAN script for the restore job. This is useful to
determine whether the selected restore options will yield the desired result in
the script. You can also manually copy and save the generated RMAN script to
your computer and later execute the script from the command line.
From the CommCell Browser, navigate to Client Computers |
<Client> | Oracle.
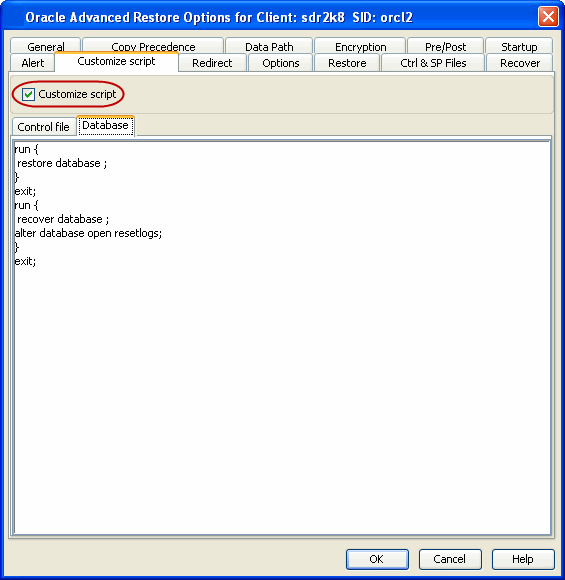
In addition to previewing the RMAN script, you can also modify the script
from the CommCell Console. This is useful when you want to include the RMAN
commands that is not supported by the software.
From the CommCell Browser, navigate to Client Computers |
<Client> | Oracle.
Right-click the <Instance>, and select Restore.
Click Advanced.
Click the Customize Script tab.
Select the Customize Script checkbox.
The script for the
control file restore will be generated.
Click the Database tab to view the script for the database
restore.
Name of the client defined in the CommCell Console and the client
name from where RMAN script runs. This parameter is optional. It is
primarily used in a clustered environment.
[CvInstanceName]
[CvInstanceName]
<Instance_Name>
Example:
[CvInstanceName]
instance_name
Name of the Calypso instance installed on the client from
where the RMAN script runs.
This parameter
is optional.
In cases of
multiple instances of the software, the first installed instance would
be 'Instance001'.
[CvOraSID]
[CvOraSID]
<oracle_sid>
Example:
[CvOraSID]
DB1
Name of the Oracle System ID (SID). This parameter is used during multi
stream backups and also when the Oracle database name is different from
Oracle SID. It is also used for multistream restores to get single job
id. This parameter is optional.
In case of a duplicate database
restore, CvOraSID must be the destination SID name, otherwise in all
cases it is source SID.
[CvSrcClientName]
[CvSrcClientName]
Source_client_name
Name of the Source client defined in CommServe for which restore should
look for backup pieces. It will be needed for cross-machine/duplicate
restores to get correct backup piece of the required oracle instance
when there are conflicting backup pieces between two oracle instances on
different clients.
Prior to running the RMAN scripts from the RMAN command line, do the
following:
1.
Add the environmental variables for the client and instance on which the
iDataAgent is installed.
From the RMAN command prompt, connect to the target database.
rman target sys/sys@<databasename>
5.
Execute the RMAN script.
@restore.txt
The
restore and recover processes are run as separate RMAN run blocks and hence
when resumed, the job is restarted from the last failed RMAN run block.
In order to perform a restore operation, the database should be in the MOUNT
mode. If the database is not in mounted state, you are prompted to switch
the database to the mounted state and then perform the restore.
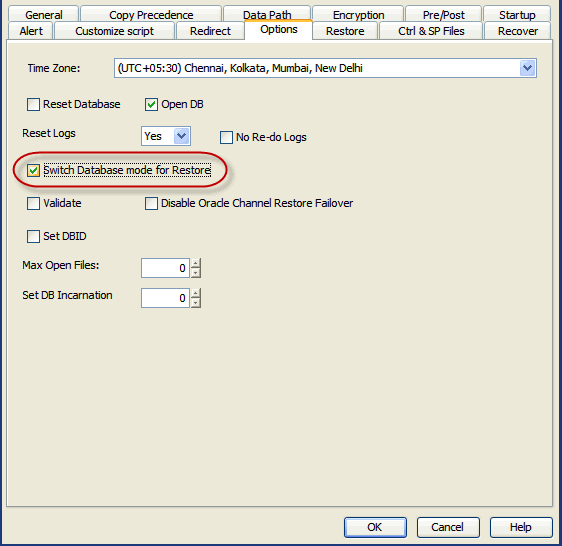
A static listener must be configured for database restores with the switch
database mode when the Oracle database is in open mode. See
When do we configure a static listener
for additional information.
Use the following steps to automatically switch the database to mount mode
prior to restore:
From the CommCell Browser, navigate to Client Computers |
<Client> | Oracle.
Right-click the <Instance>, point to All Tasks
and then click Restore.
Click Advanced.
Clickthe Options tab.
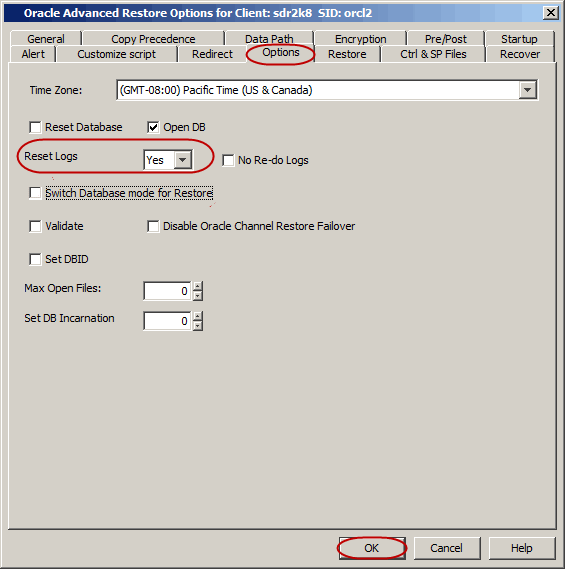
Select Switch Database mode for Restore.
Click OK.
Sometimes, the database may not restart after switching the database
during restore on Linux clients. To resolve this issue, see
Restore - Troubleshooting.
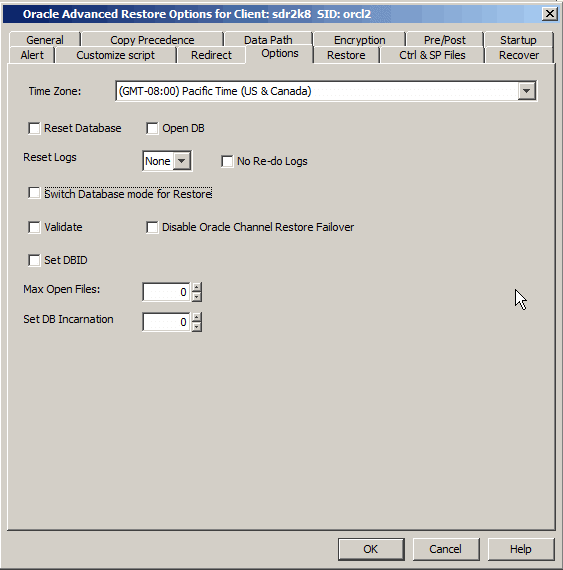
When you perform a point-in-time recovery of an Oracle database with RESETLOGS, a new incarnation of the database is created. All archive log files
generated after resetting the logs will be associated to the new incarnation.
However, in order to perform a point-in-time recovery from a backup of a
previous incarnation, you need to reset the current incarnation to the previous
incarnation value. Use the following steps to set
the incarnation value:
From the CommCell Browser, navigate to Client Computers |
<Client> | Oracle.
Right-click the <Instance>, point to All Tasks
and then click Restore.
Click Advanced.
Click Options tab.
Select the database incarnation value from Set DB Incarnation
list.
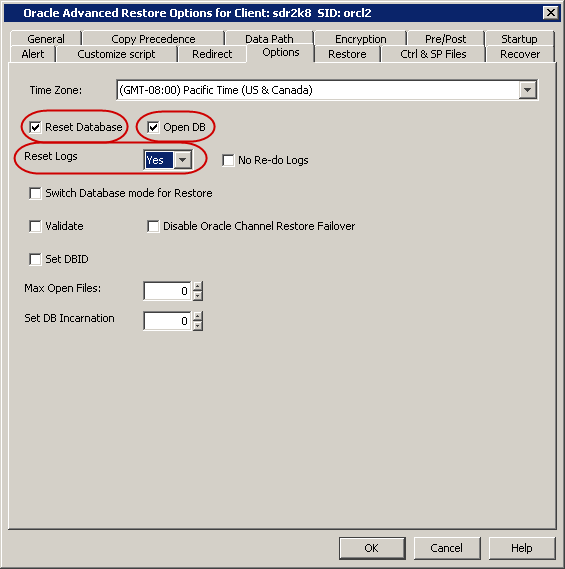
By default, the database is not reset. After resetting the logs to open
state, you can reset the database. Use the following steps to reset the database after a restore:
From the CommCell Browser, navigate to Client Computers |
<Client> | Oracle.
Right-click the <Instance>, point to All Tasks
and then click Restore.
During restore operations, RMAN automatically looks for another copy of the
file under the following circumstances:
a backup piece is corrupted or deleted
a media agent is offline
a block in the backup is corrupted within the latest full backup
If it is not available in the other copy, RMAN will use older versions of the
file, if available. When multiple channels are available for the same device
type, RMAN will automatically retry on another channel. RMAN continuously searches all prior backups until it has exhausted all
possibilities. This process will delay the restore jobs.
Use
the following steps to disable the failovers during restore and prevent job
delays:
From the CommCell Browser, navigate to Client Computers |
<Client> | Oracle.
Right-click the <Instance>, point to All Tasks
and then click Restore.
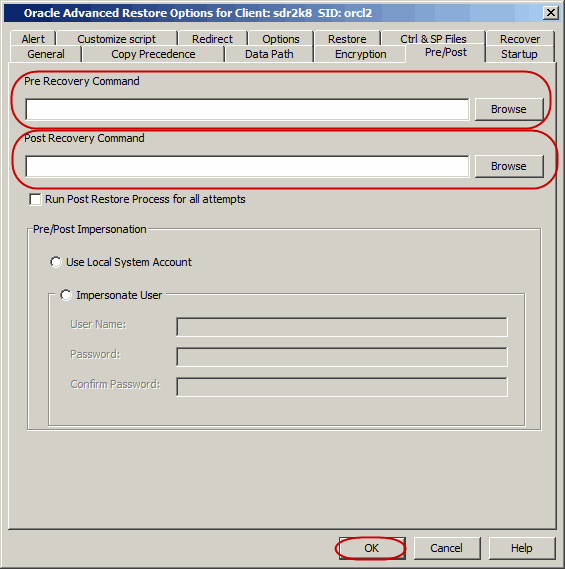
You can run batch files or shell scripts before and/or
after restore jobs. Use the following steps to setup a process before or
after a restore job:
From the CommCell Browser, navigate to Client Computers |
<Client> | Oracle.
Right-click the <Instance>, point to All Tasks
and then click Restore.
Click OK.
Click
Advanced.
Click Pre/Post
tab.
Type the path for
the batch file in the Pre Recovery Command box or click Browse to
select the batch file to perform a process before the restore job.
Type the path for
the batch file in the Post Recovery Command box or click Browse to
select the batch file to perform a process after the restore job.
On Windows, select one of the following options:
Use Local Accounts - Select this option if the local account has permissions to
execute the processes on the destination client.
Impersonate User - Select this option and enter the username and
password, that has the permissions to execute the processes on the
destination client.
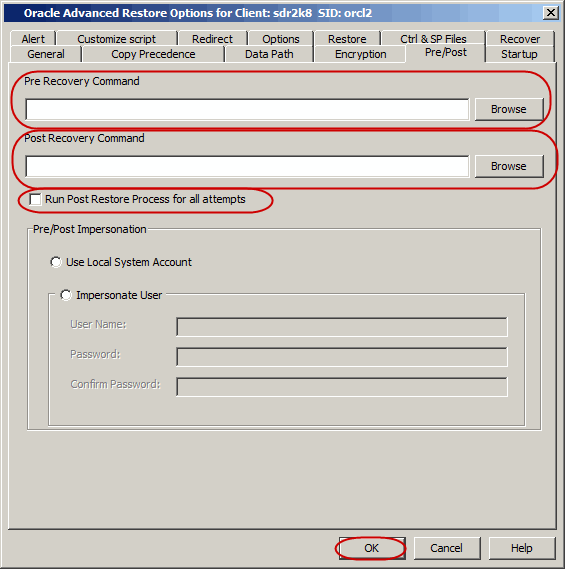
By default, a specified post process command is executed only on successful
completion of the restore operation.
Perform a restore operation even if the restore operation did not complete
successfully. This may be useful to bring a database
online or release a snapshot. Use the following steps to run a post process:
From the CommCell Browser, navigate to Client Computers |
<Client> | Oracle.
Right-click the <Instance>, point to All Tasks
and then click Restore.
Click OK.
Click
Advanced.
Click the Pre/Post
tab.
Enter the path for the batch file in the Post Recovery Command
box or click Browse to
select the batch file.
Select the Run Post Process for all attempts check box.
If you perform a validating restore job, the RMAN will stimulate a restore
job and verifies whether the backup copies of data and logs required for the
restore are intact and usable.
Use the following steps to validate a restore job:
From the CommCell Browser, navigate to Client Computers |
<Client> | Oracle.
Right-click the <Instance>, point to All Tasks
and then click Restore.
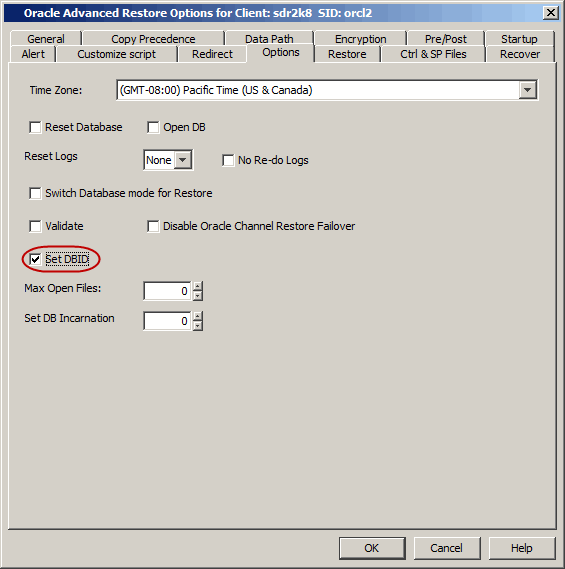
The Database Identifier (DBID) is an internal, uniquely generated number that will distinguish the
target database from the rest of the databases that have the same name in the
recovery catalog. Oracle creates this number automatically when you create the
database. The DBID is set while restoring the control file to differentiate the
database for which the control file is restored.
Use the following steps to set
the DBID and differentiate the database:
From the CommCell Browser, navigate to Client Computers |
<Client> | Oracle.
Right-click the <Instance>, point to All Tasks
and then click Restore.
Each Oracle database has a redo log. This redo log records all changes made
in datafiles. When you run your database in NOARCHIVELOG mode, you disable the
archiving of the redo log.
By default, the No Redo Log is disabled. Hence, While restoring the database, RMAN
will search for archived re-do logs after applying incremental backup data. Setting
No Re-do Logs will enable the RMAN to suppress the
archived re-do logs so that only data from incremental backups is restored.
Enable No Re-do logs when you perform a point-in-time restore of a database that
was backed up in NOARCHIVELOG mode.
Use the following steps to enable No Re-do Logs and perform a restore
operation:
From the CommCell Browser, navigate to Client Computers |
<Client> | Oracle.
Right-click the <Instance>, point to All Tasks
and then click Restore.
You can perform a restore operation faster when you set a maximum
number of concurrent open datafiles for RMAN to read simultaneously. Use
the following steps to enhance your restore operation:
From the CommCell Browser, navigate to Client Computers |
<Client> | Oracle.
Right-click the <Instance>, point to All Tasks
and then click Restore.
Click Advanced.
Click Options tab.
Select the number of open files from Max Open Files list.
Once you initiate the restore operation, a restore job is generated in the Job
Controller. Jobs can be managed in a number of ways. The following sections provide
information on the different job management options available:
Jobs that fail to complete successfully are automatically restarted based on
the job restartability configuration set in the Control Panel. Keep in mind that changes
made to this configuration will affect all
jobs in the entire CommCell.
To Configure the job restartability for a specific job, you can modify the
retry settings for the job. This will override the setting in the Control Panel. It is also possible to override the default CommServe configuration for individual
jobs by configuring retry settings when initiating the job. This configuration,
however, will apply only to the specific job.
Restore jobs for this Agent are resumed from the point-of-failure.
Configure Job Restartability at the CommServe Level
From the CommCell Browser, click Control Panel icon.
Select
Job Management.
Click Job Restarts tab and select a Job Type.
Select Restartable to make the job restartable.
Change the value for Max Restarts to change the maximum number of
times the Job Manager will try to restart a job.
Change the value for Restart Interval (Mins) to change the time
interval between attempts for the Job Manager to restart the job.
The following controls are available for running jobs in the Job Controller window:
Suspend
Temporarily stops a job. A suspended job is not
terminated; it can be restarted at a later time.
Resume
Resumes a job and returns the
status to Waiting, Pending, Queued, or Running. The status depends on
the availability of resources, the state of the Operation Windows, or
the Activity Control setting
Kill
Terminates a job.
Suspending a Job
From the Job Controller of the CommCell Console, right-click the job and
select Suspend.
The job status may change to Suspend Pending
for a few moments while the operation completes. The job status then changes
to Suspended.
Resuming a Job
From the Job Controller of the CommCell Console, right-click the job and
select Resume.
As the Job Manager attempts to restart the job,
the job status changes to Waiting, Pending, or Running.
Killing a Job
From the Job Controller of the CommCell Console, right-click the job and
select Kill.
Click Yes when the confirmation prompt
appears if you are sure you want to kill the job. The job status may
change to Kill Pending for a few moments while the operation
completes. Once completed, the job status will change to Killed and
it will be removed from the Job Controller window after five minutes.
If a restore job fails to complete successfully, you can resubmit the job without
the need to reconfigure the original job's restore options using the Resubmit
Job feature. When a job is resubmitted, all the original options, restore destinations,
and other settings configured for the job remain in tact.
Resubmit a Restore Job
From the CommCell Browser, right-click a client computer whose data recovery
history you want to view, click View,then click to view a job
history.
From the Job History Filter dialog box, select Restore.
If you want to view more advanced options for restores, from the Job
History Filter, select Restore, then click Advanced.
From the Data Recovery History Advanced Filter select the destination
client computer of the restores you would like to view, then click OK.
The system displays the results of the options you selected in the Data
Recovery Job History window.
Several additional options are available to further refine your restore
operations. The following table describes these options, as well as the steps to
implement them.
Be sure to read the overview material referenced for each feature prior to using
them.
Option
Description
Related Topics
Use hardware revert capability if available
This option allow you to revert the data to the time when the snapshot was
created. Selecting this option brings back the entire LUN to the point when the
snapshot was created, overwriting all modifications to the data since the
snapshot creation. This option is only available if the storage array used for SnapProtect Backup supports the revert operation.
From the CommCell Browser, navigate to Client Computers |
<Client> | Oracle.
Right-click the <Instance> point to All Tasks,
and then click Browse
Backup Data.
Click OK.
In the right pane of the Browse window, select the
data you want to restore and click Recover All Selected.
Click Advanced.
Select Use hardware revert capability if available check box.
Click OK.
Startup Options
The Startup Options are used by the Job Manager to set priority for resource
allocation. This is useful to give higher priority to certain jobs. You can set
the priority as follows:
From the CommCell Browser, navigate to Client Computers |
<Client> | Oracle.
Right-click the <Instance> point to All Tasks,
and then click Browse
Backup Data.
Click OK.
In the right pane of the Browse window, select the
data you want to restore and click Recover All Selected.
Click Advanced.
Click Startup tab.
Select Change Priority.
Select a priority number - 0 is the highest priority and 999 is the
lowest priority.
Select the Start up in suspended State check box to start the job
in a suspended state.
By default, the system retrieves data from the storage policy copy with
the lowest copy precedence. If the data was pruned from the primary
copy, the system automatically retrieves data from the other copies of
the storage policy in the lowest copy precedence to highest copy
precedence order. Once the data is found, it is retrieved, and no
further copies are checked.
You can retrieve data from a specific
storage policy copy (Synchronous Copy or Selective Copy). If data does
not exist in the specified copy, the data retrieve operation fails even
if the data exists in another copy of the same storage policy. Follow
the steps given below to retrieve the data from a a specific storage
policy copy:
From the CommCell Browser, navigate to Client Computers |
<Client> | Oracle.
Right-click the <Instance> point to All Tasks,
and then click Browse
Backup Data.
Click OK.
In the right pane of the Browse window, select the
data you want to restore and click Recover All Selected.
Click Advanced.
Click Copy Precedence tab.
Select the Restore from copy precedence
check box.
The data recovery operations use a default Library, MediaAgent, Drive
Pool, and Drive as the Data Path. You can use this option to change the
data path if the default data path is not available. Follow the steps
given below to change the default data path:
From the CommCell Browser, navigate to Client Computers |
<Client> | Oracle.
Right-click the <Instance> point to All Tasks,
and then click Browse
Backup Data.
Click OK.
In the right pane of the Browse window, select the
data you want to restore and click Recover All Selected.
Click Advanced.
Click Data Path tab.
Select the MediaAgentfrom Use MediaAgent
list.
Select the Library from Use Library list.
Select the drive pool and drive from Use Drive Pool and Use Drive
lists for optical and tape
libraries.
Select the name of the Proxy server from Use Proxy
list, if you
wish to restore using a proxy server.
If the client's data is encrypted with a pass phrase, you must enter
the pass-phrase to start the data recovery operation. Follow the steps
given below to enter the pass-phrase:
From the CommCell Browser, navigate to Client Computers |
<Client> | Oracle.
Right-click the <Instance> point to All Tasks,
and then click Browse
Backup Data.
Click OK.
In the right pane of the Browse window, select the
data you want to restore and click Recover All Selected.
Click Advanced.
Click Encryption tab.
Type the pass phrase in Pass Phrase box.
Re-type the pass phrase in Re-enter Pass Phrase box.
This option enables users or user groups to get automatic notification on the
status of the data recovery job. Follow the steps given below to set up the
criteria to raise notifications/alerts:
From the CommCell Browser, navigate to Client Computers |
<Client> | Oracle.
Right-click the <Instance> point to All Tasks,
and then click Browse
Backup Data.
Click OK.
In the right pane of the Browse window, select the
data you want to restore and click Recover All Selected.
Click Advanced.
Click Alerts tab.
Click Add Alert.
From the Add Alert Wizard box, select the required threshold and
notification criteria and click Next.
Select the required notification types and click Next.
The CommCell Readiness Report provides you with vital information, such as
connectivity and readiness of the Client, MediaAgent and CommServe. It is useful
to run this report before performing the data protection or recovery job. Follow the steps
given below to generate the report:
From the Tools menu in the CommCell Console, click Reports.
Navigate to Reports | CommServe | CommCell Readiness.
Click the Client tab and click the Modify button.
In the Select Computers dialog box, clear the Include All
Client Computers and All Client Groups check box.
The Restore Job Summary Report provides you with information about all the
data recovery jobs that are run in last 24 hours for a specific client and
agent. You can get
information such as failure reason, failed objects, job options etc. It is useful
to run this report after performing the restore. Follow the steps
given below to generate the report:
From the Tools menu in the CommCell Console, click Reports.
Navigate to Reports | Jobs | Job Summary.
Click Data Recovery on the General tab in the right
pane.
On the Computers tab, select the client and the agent for which
you want to run the report.